In the early days of public cloud adoption, the promise was clear and compelling: businesses could expect significant cost savings, unparalleled scalability, robust security, and a highly reliable platform. These benefits were supposed to eliminate the need for over-provisioning, reduce the burden of managing data centers, and provide a fail-safe environment where resources could be provisioned on demand to meet stringent service-level agreements (SLAs).
The Cloud Cost Challenges
However, the landscape of cloud computing has evolved, and with it, the challenges have multiplied. While the core benefits of the cloud remain intact, the costs associated with these platforms are rising at an alarming rate. This rise is not happening in a vacuum; it’s the result of a confluence of economic and industry-specific factors that are driving up the expenses associated with operating in the cloud. Let’s explore these key drivers in more detail:

1. Inflation
Inflation affects virtually every aspect of the global economy, and cloud computing is no exception. As the cost of goods and services rises, cloud providers face increased expenses across the board—from the electricity needed to power massive data centers to the raw materials used in building and maintaining hardware infrastructure. These rising operational costs inevitably trickle down to customers in the form of higher prices for cloud services. This is particularly challenging for businesses that rely heavily on cloud services, as their budgets are stretched thin by these incremental price increases.
2. Surging Energy Prices
Energy is a critical component of cloud computing infrastructure. Data centers, which house the servers and storage systems that power cloud services, consume vast amounts of electricity. This energy is required not only to keep the hardware running but also to maintain the optimal environmental conditions (such as cooling) necessary to prevent overheating and ensure reliable performance. The surge in energy prices makes it more expensive for cloud providers to deliver their services. As a result, businesses that depend on these services are seeing an increase in their cloud bills.
3. Escalating Hardware Costs
The hardware that underpins cloud infrastructure—servers, storage devices, networking equipment, and more—has also become more expensive. Several factors contribute to the rising cost of hardware:
- Supply Chain Disruptions: The global supply chain has faced significant disruptions in recent years, from the COVID-19 pandemic to semiconductor shortages. These disruptions have led to delays in the production and delivery of critical components, driving up the price of hardware.
- Increased Demand: As more businesses migrate to the cloud, and the increased adoption of AI, the demand for high-performance hardware has skyrocketed. This surge in demand puts additional pressure on manufacturers, contributing to higher prices for cloud providers and, by extension, their customers.
Technological Advancements: While technological advancements often lead to more efficient and powerful hardware, they also come with higher costs. Cutting-edge technologies such as advanced processors, high-speed networking, and specialized AI accelerators require significant investment, which is reflected in the price of cloud services that leverage these innovations.
4. Growing Personnel Expenses
The human element of cloud computing cannot be overlooked. Managing and maintaining cloud infrastructure requires a skilled workforce, including engineers, developers, security experts, and support staff. As cloud platforms become more complex and sophisticated, the demand for highly skilled personnel has increased. However, this demand is met with a limited supply of qualified professionals, leading to higher salaries and compensation packages. Read more about how to structure your IT department for digital transformation.
Several factors contribute to the rising personnel costs:
- Talent Shortage: The rapid growth of cloud computing has outpaced the availability of skilled professionals. This talent shortage drives up the cost of hiring and retaining top-tier talent, especially in specialized areas such as cloud architecture, cybersecurity, and AI integration.
Increased Competition: Cloud providers and enterprises alike are competing for the same pool of skilled workers. This competition not only drives up salaries but also increases the cost of recruitment and retention efforts, including benefits, training, and career development programs.
The Rising Complexity of Cloud Platforms
The complexity of cloud platforms is another critical issue compounding these financial pressures. Cloud computing has never been a simple plug-and-play solution; it requires a deep understanding of various services, tools, and architectures. As cloud providers continue to expand their offerings, the learning curve for businesses becomes steeper. While this complexity enables more advanced use cases, it also presents significant challenges:

1. Service Proliferation
Cloud providers continually roll out new services and features, which, while valuable, add layers of complexity. Navigating these services requires a deep understanding of cloud architectures and best practices, making it difficult for businesses to keep up without specialized expertise.
2. Integration Challenges
Integrating cloud services with existing on-premises systems or other cloud environments can be challenging. The more complex the cloud environment, the more difficult it is to ensure seamless integration, leading to potential inefficiencies and increased costs.
3. Security and Compliance
As cloud environments grow more complex, so too do the challenges associated with securing them. Ensuring that all cloud services meet regulatory compliance standards (such as GDPR, PCI, or SOC2) requires significant effort and resources. Failing to do so can result in costly fines and reputational damage.
4. Skilled Professionals
Finding skilled professionals who can navigate this complexity is becoming increasingly difficult. The talent shortage in cloud computing is well-documented, and the demand for experts who can manage these sophisticated environments far exceeds the supply. This scarcity drives up the cost of hiring and retaining qualified personnel, further exacerbating the financial challenges that businesses face.
The Impact on Cloud Customers
For businesses relying on cloud services, these rising costs can have a significant impact on their bottom line. Cloud computing was initially embraced for its cost-effectiveness and scalability, but as prices continue to rise, companies may find themselves facing unexpected financial pressures. The combination of the cost increasing elements discussed above creates a perfect storm that can erode the cost advantages of the cloud.
Without careful management and optimization, businesses may see their cloud expenses balloon, leading to reduced profitability and missed revenue opportunities. This underscores the importance of not only choosing the right cloud services but also implementing strategies to control and optimize cloud spending in the face of these rising costs.
As a result, what was once seen as a cost-effective alternative to on-premises infrastructure is now a significant financial burden for many organizations. If cloud environments are not optimized correctly, businesses risk depleting their already thin profit margins, particularly in an economic climate where every dollar counts. The reality is stark: companies that fail to manage their cloud costs effectively may find themselves missing revenue targets, struggling to justify their cloud investments, and facing financial strain in an already challenging market.
The Impact on Startups and SMBs
For startups and small to medium-sized businesses (SMBs), the situation is particularly dire. These organizations often operate with limited budgets and tight margins. The rising costs of cloud computing, combined with the difficulty of finding skilled cloud professionals, can make it seem like an insurmountable challenge to stay competitive.
In such a scenario, the temptation might be to revert to on-premises infrastructure. However, this path comes with its own set of challenges—namely, the need to manage physical hardware, maintain security, and ensure reliability. This approach could divert precious resources away from core business functions, such as product development and customer engagement.
Strategies to Tame Cloud Costs and Complexity
While the challenges of rising cloud costs and increasing complexity are real, they are manageable with the right strategies. Here are some practical approaches businesses can adopt:

1. Standardized Architectures
Implementing standardized cloud architectures across your organization ensures consistency, reduces complexity, and minimizes errors. By establishing best practices and using predefined solutions for deploying cloud resources, businesses can streamline operations, improve efficiency, and reduce the likelihood of costly mistakes. Standardization also makes it easier to manage and scale cloud environments, as well as train new staff on established processes.
2. Prioritize Security and Compliance
Security and compliance should be top priorities in any cloud strategy. Implement robust security practices, such as Identity and Access Management (IAM), encryption, and regular security audits, to protect your data and infrastructure. Automating compliance checks and utilizing platform-specific security tools can help ensure your environment meets regulatory requirements, reducing the risk of fines and breaches. By proactively addressing security and compliance, businesses can avoid costly incidents and maintain customer trust.
3. Automation
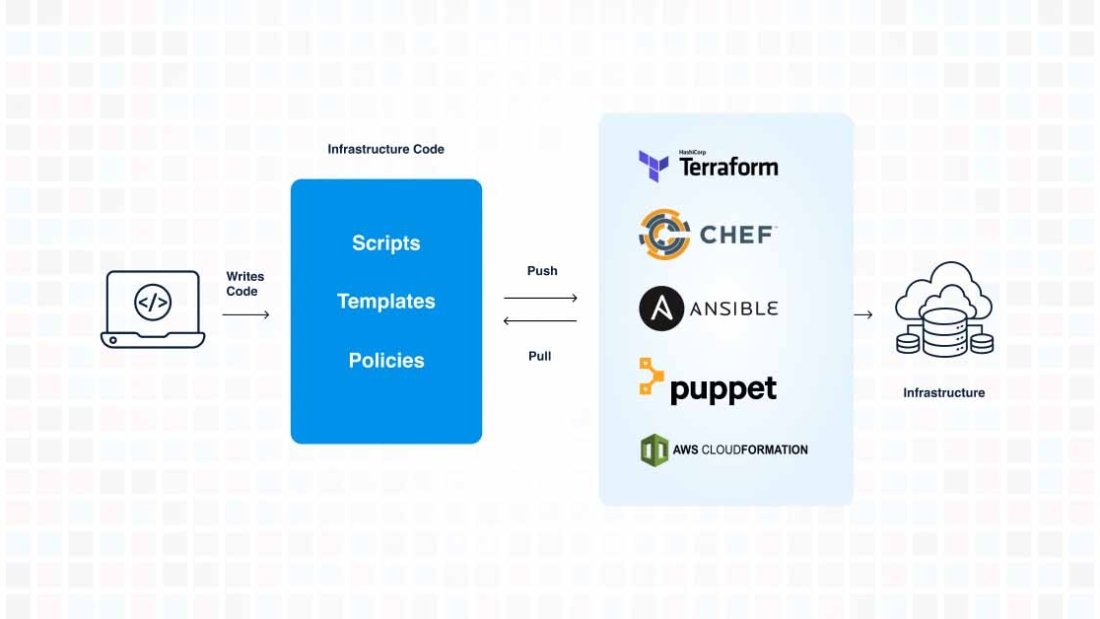
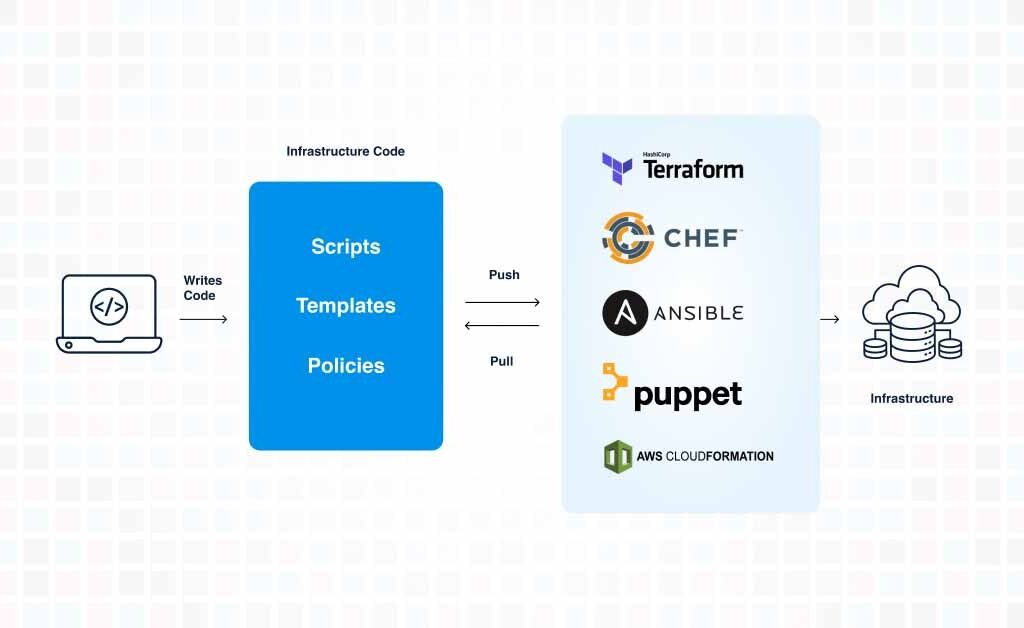
Automation is key to reducing manual effort and improving operational efficiency in cloud environments. Use Infrastructure as Code (IaC) tools to automate the provisioning, scaling, and management of cloud resources. This allows you to quickly start and shut down environments with minimal effort, ensuring that resources are only used when needed, which can significantly reduce costs. Automation also helps enforce consistency across deployments, reducing the risk of human error.
4. Training
Investing in training for your IT staff is crucial for managing complex cloud environments effectively. Encourage key team members to obtain certifications in cloud platforms like AWS, Azure, or Google Cloud. Well-trained staff can make better decisions, optimize resources, and ensure the security and reliability of your cloud infrastructure. If in-house expertise is lacking, consider partnering with a Managed Service Provider (MSP) or hiring cloud consultants to fill the gap. Proper training and expertise can prevent costly mistakes and maximize the value of your cloud investments.
5. Well-Defined Environments
Clear separation and definition of cloud environments are essential for cost management and operational efficiency. Production environments should be fully provisioned with all necessary resources, security measures, and performance optimizations. On the other hand, development and test environments should be provisioned with minimal resources to save costs. This approach ensures that production remains stable and secure while keeping non-essential costs in check for lower-priority environments.
6. Cost Optimization Reviews
Cost optimization is an ongoing process that requires regular attention. Periodically review your cloud spending to identify inefficiencies, such as underutilized resources or overprovisioned services. Utilize tools like AWS Cost Explorer, Azure Cost Management, or Google Cloud’s Cost Management tools to monitor and manage expenses. Implement strategies such as rightsizing, automation, and using reserved instances to reduce costs. Continuous cost optimization ensures that your cloud environment remains financially sustainable and aligned with your business goals.
7. Do Not Reinvent The Wheel
Instead of trying to reinvent the wheel, it’s often more efficient to rely on proven solutions that are designed to address the complexities and challenges of cloud computing. These solutions can bring expertise and pre-built architectures to the table, allowing you to focus on your core business objectives while ensuring that your cloud infrastructure is optimized, secure, and cost-effective.
While these strategies are essential for businesses to realize cost benefits, they demand significant time and resources—efforts that could be better spent on developing applications that differentiate your business.
The Solution: Optimized Cloud Adoption with CloudKitect
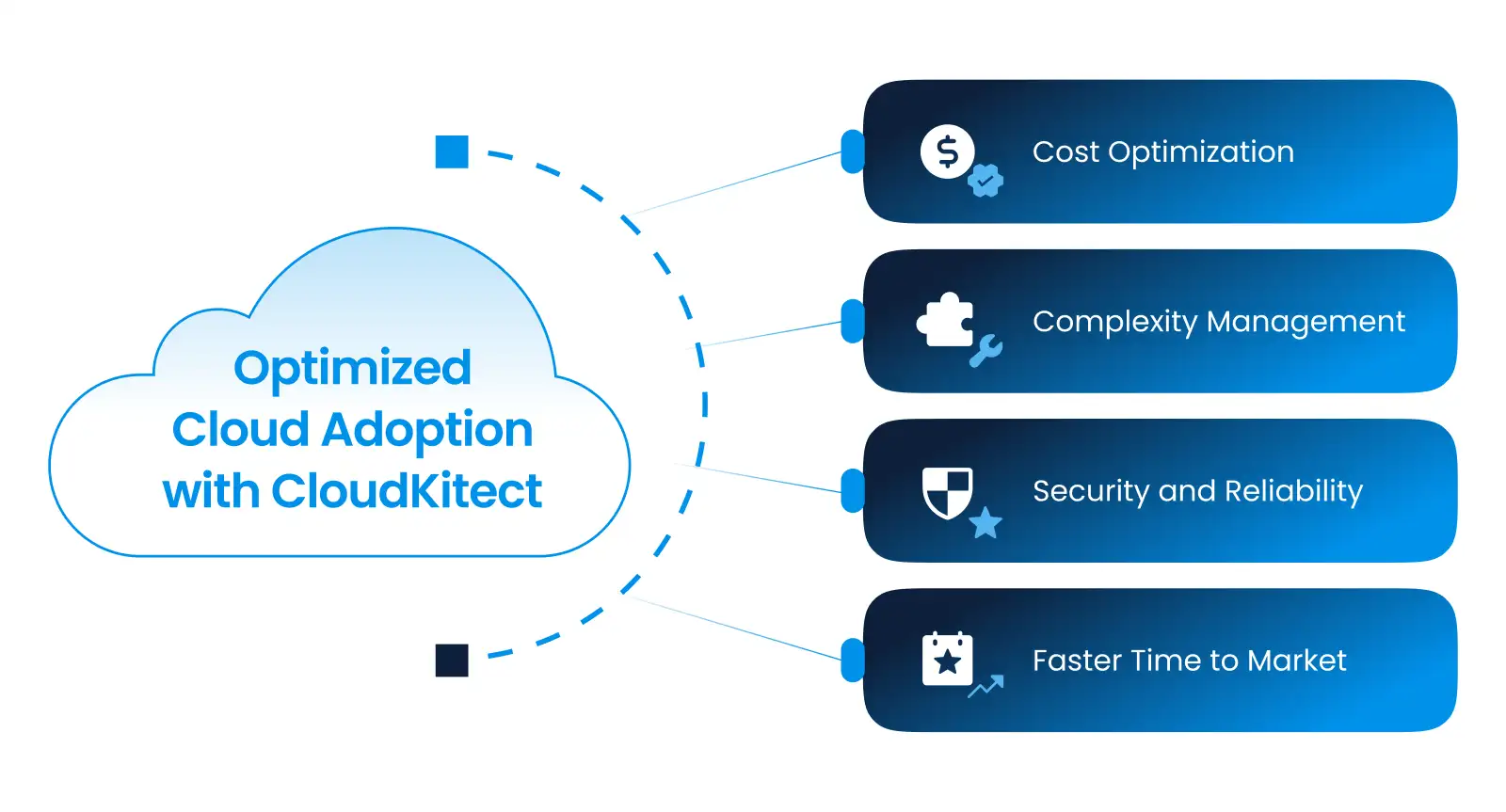
CloudKitect addresses the key pain points that businesses face in today’s cloud landscape:
- Cost Optimization: Through intelligent design and automation, CloudKitect helps businesses avoid the pitfalls of over-provisioning and underutilization, ensuring that every dollar spent on cloud resources delivers maximum value.
- Complexity Management: CloudKitect’s advanced architectures simplify the deployment and management of cloud environments, reducing the need for highly specialized—and often expensive—talent.
- Security and Reliability: By leveraging AI-driven strategies, CloudKitect ensures that businesses can maintain the highest levels of security and reliability without the need for extensive in-house expertise.
- Faster Time to Market: With streamlined processes and automated workflows, CloudKitect empowers businesses to accelerate their product development cycles, giving them a competitive edge in the market. Click here, to learn more about Cloudkitect features.
Conclusion
While the challenges of rising costs and increasing complexity in cloud computing are real, they are not insurmountable. With the right tools and strategies, businesses can still reap the benefits of the cloud while controlling costs and mitigating risks. CloudKitect offers a powerful solution for organizations looking to optimize their cloud environments, transforming IT departments from cost centers into engines of growth and profitability. By partnering with CloudKitect, businesses can navigate the complexities of cloud computing with confidence, ensuring they remain competitive in an increasingly digital world.
Talk to Our Cloud/AI Experts
Search Blog
About us
CloudKitect revolutionizes the way technology startups adopt cloud computing by providing innovative, secure, and cost-effective turnkey AI solution that fast-tracks the digital transformation. CloudKitect offers Cloud Architect as a Service.
Related Resources