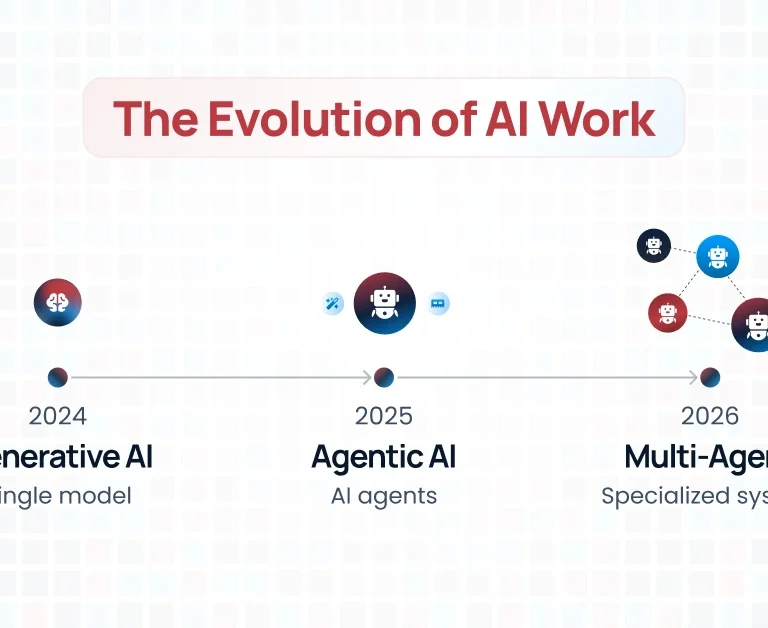

CloudKitect’s new OpenSearch serverless component streamlines the setup process of an OpenSearch cluster, making it remarkably fast and efficient. By leveraging this component, users can deploy an OpenSearch cluster in about an hour, a significant reduction from the traditional setup time. This acceleration is achieved through automated provisioning and configuration processes that handle the complexities of infrastructure setup and optimization. The component encapsulates best practices for OpenSearch deployment, ensuring a robust, scalable, and fully managed search and analytics environment with minimal manual effort. This swift deployment capability allows organizations to quickly leverage the power of OpenSearch for their search and data analytics needs, without the usual time-consuming setup hurdles.
Using only a few lines of code, your developers will be able to launch serverless OpenSearch cluster within an hour, moreover the tool is available in the programming language they are already familiar with so there is minimum learning curve.