
Search Engine vs. Vector Database: Choosing the Right Knowledge Search Tool
- Blog
- Muhammad Tahir
As organizations increasingly seek efficient ways to harness knowledge, search technologies have evolved to meet the growing demands of users. Two prominent options have emerged: search engines and vector databases. Both serve as tools for retrieving information, but they operate on fundamentally different principles and are suited to different use cases.
This blog post will delve into the differences and advantages of using search engines versus vector databases for knowledge search. By the end, you’ll have a clear understanding of when to use each and how they can complement one another.
What is a Search Engine?
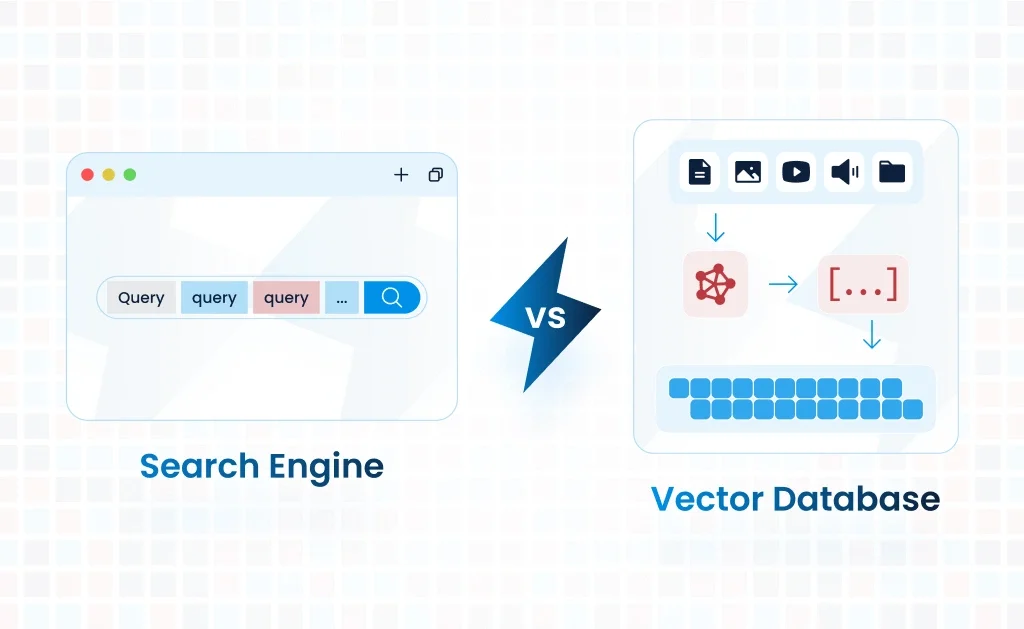
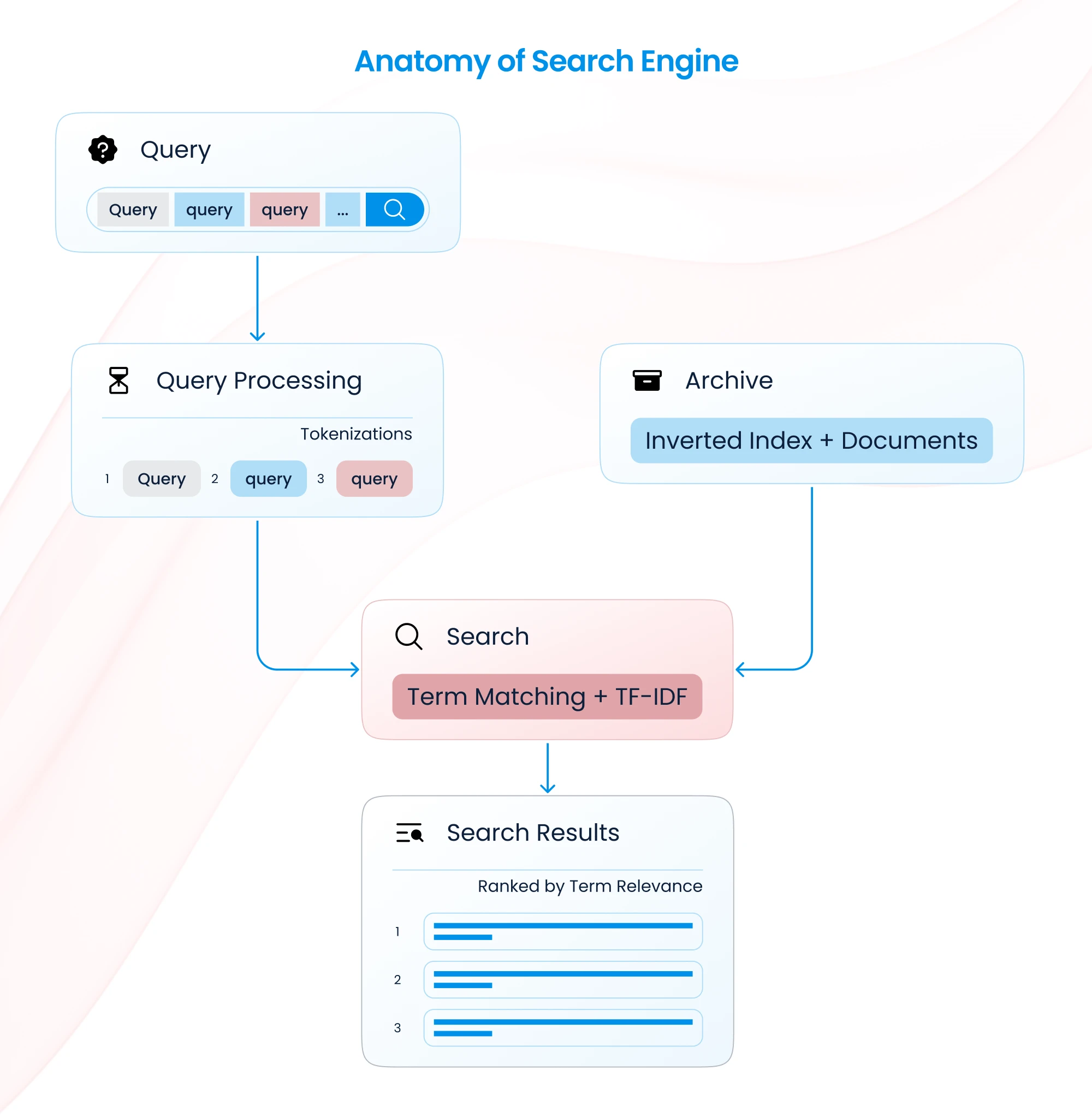
A search engine is a software system designed to perform text-based searches across a collection of indexed data. Popular examples include Elasticsearch, Solr, and web-based engines like Google. Search engines work by matching keywords in a query with the indexed content, returning results ranked by relevance.
Key Features:
- Textual Relevance: Search engines use techniques like keyword matching, Boolean queries, and TF-IDF scoring to rank results.
- Full-Text Search: They excel at finding exact matches or partial matches based on the query terms.
- Structured and Unstructured Data: Search engines can index both types of data but are traditionally optimized for text-heavy datasets.
- Scalability: Designed for handling large datasets efficiently, making them a go-to solution for enterprise-level text search.
What is a Vector Database?
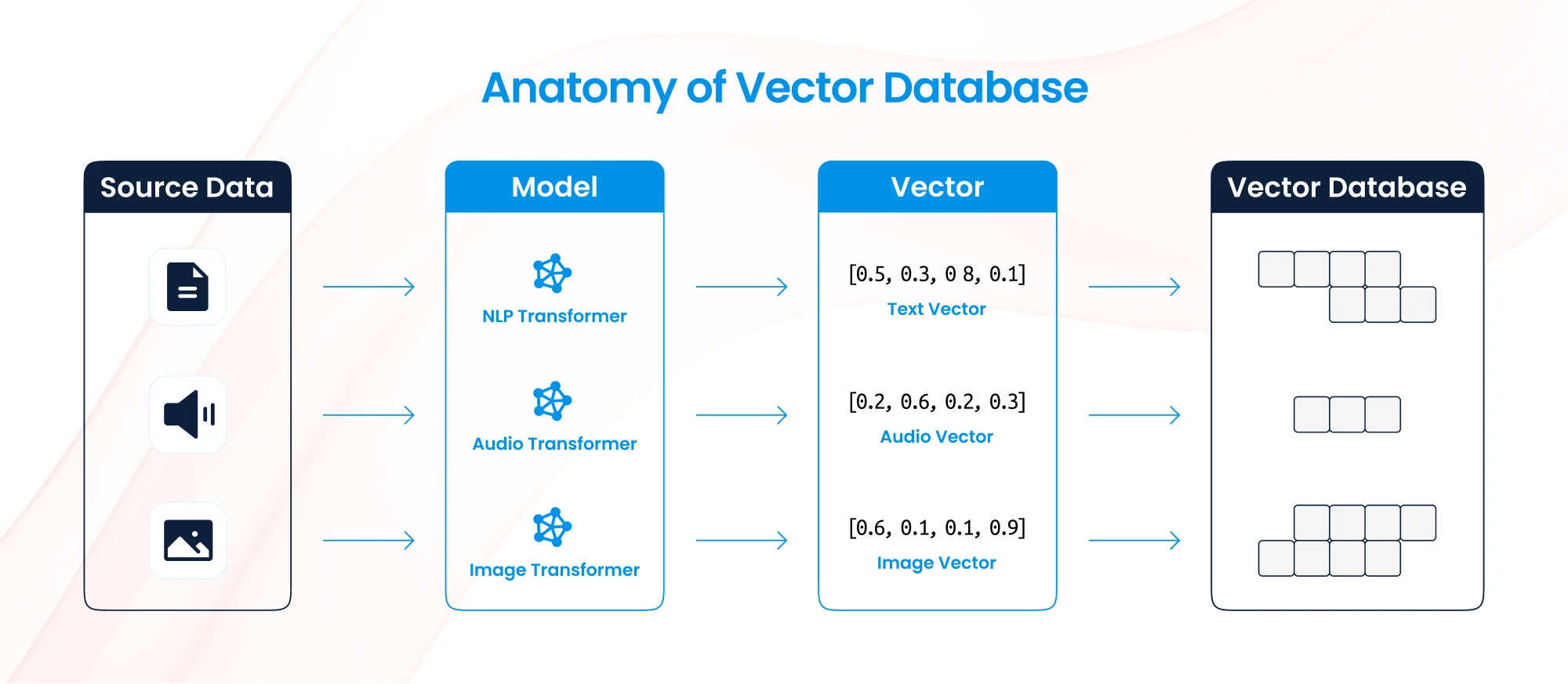
A vector database is a specialized database designed to store, index, and query high-dimensional vector representations of data. Vectors are numerical representations of data such as text, images, or audio, often generated using machine learning models like word embeddings or neural networks. One such database is Open Search from aws, click here if you want to learn about OpenSearch as a vector database.
Key Features:
- Semantic Search: Vector databases enable searches based on meaning or context rather than exact keywords.
- Multimodal Data Support: They can handle embeddings of diverse data types (e.g., text, images, videos).
- Similarity Search: Results are ranked based on their similarity to the query vector, often using distance metrics like cosine similarity or Euclidean distance.
- AI Integration: Ideal for applications that leverage AI models, such as recommendation systems, chatbots, and contextual knowledge retrieval.
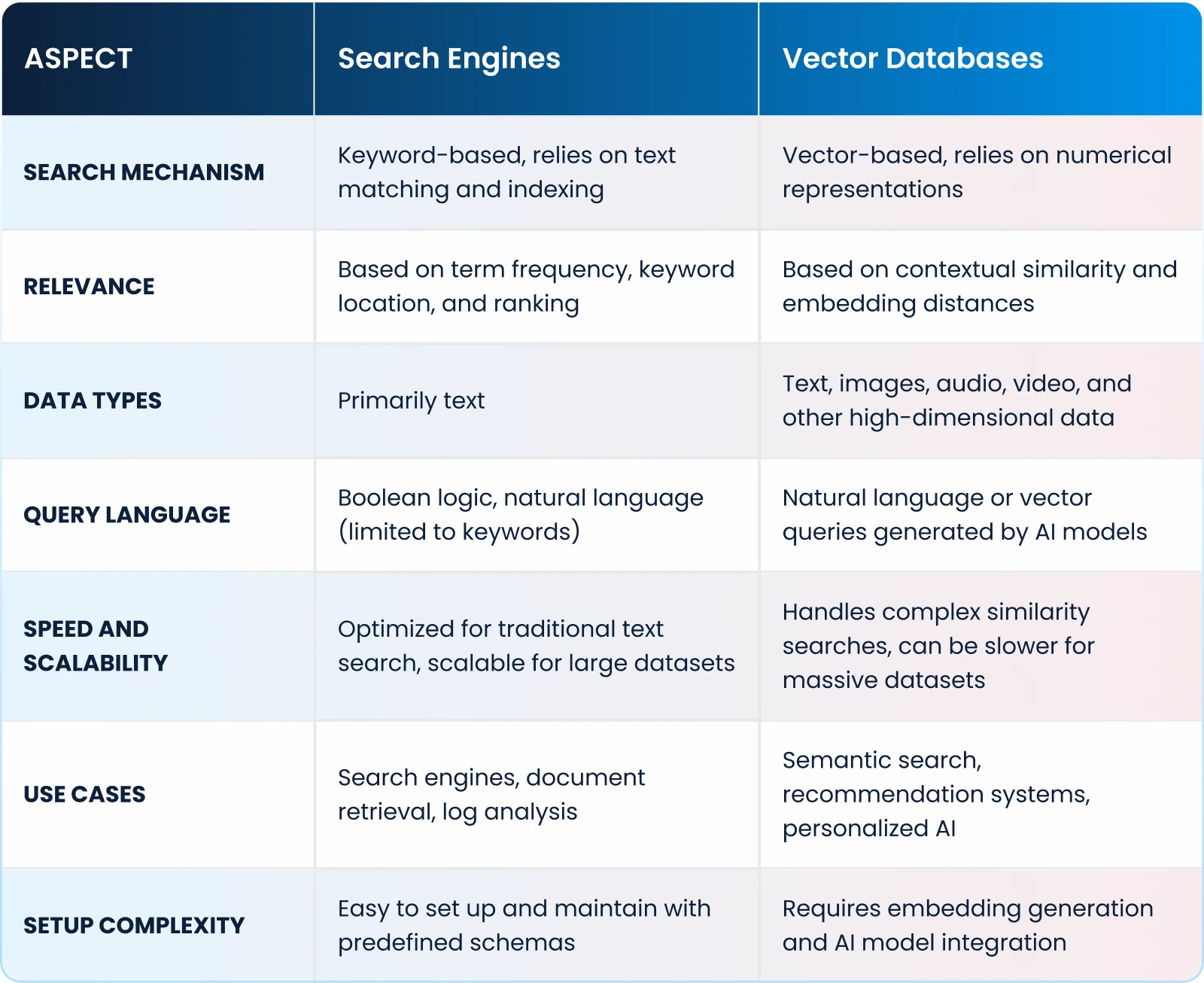
Differences Between Search Engines and Vector Databases
Advantages of Search Engines
- Proven Scalability:
Search engines like Elasticsearch and Solr are battle-tested and can handle billions of documents with low latency. - Cost Efficiency:
Well-suited for text-based data, search engines are often more cost-effective compared to vector databases, especially for structured data. - Exact Keyword Matching:
For use cases like document retrieval or log analysis, keyword matching provides highly precise results. - Mature Ecosystem:
With decades of development, search engines come with extensive community support, plugins, and integrations. - Custom Ranking:
Relevance ranking can be customized using advanced scoring techniques, filters, and aggregations.
Advantages of Vector Databases
- Semantic Understanding:
Vector databases excel at understanding context and meaning. A search for “artificial intelligence” will retrieve related terms like “machine learning” and “AI” without needing exact matches. - Support for Multimodal Data:
They can store and query embeddings for text, images, audio, and video, making them ideal for diverse datasets. - AI-Driven Applications:
By leveraging AI-generated embeddings, vector databases enable features like personalized recommendations, contextual search, and chatbot responses. - Future-Proof for AI:
As organizations increasingly adopt AI, vector databases are well-positioned to integrate with modern machine learning workflows. - Enhanced User Experience:
Semantic search powered by vector databases delivers more relevant and intuitive results, improving user satisfaction.
When to Use Search Engines
- Keyword-Driven Search: For applications like enterprise document retrieval, web searches, and log analysis.
- Static Datasets: When data changes infrequently and keyword relevance is sufficient.
- Cost-Sensitive Projects: For simple, text-based use cases where cost-efficiency is a priority.
When to Use Vector Databases
- Semantic Knowledge Retrieval: When understanding context and meaning is critical, such as in customer support systems or AI assistants.
- Multimodal Data Queries: When dealing with diverse data types like text, images, and audio.
- Dynamic and AI-Driven Workflows: For applications requiring frequent updates and AI model integration, such as recommendation engines.
Combining the Two: A Hybrid Approach
In many scenarios, search engines and vector databases can complement each other. For instance:
- Use a search engine for keyword-based filters and constraints.
- Use a vector database for semantic search and similarity-based ranking.
This hybrid approach ensures fast and accurate results, leveraging the strengths of both systems.
Conclusion: Tailoring the Right Tool for Your Needs
The choice between a search engine and a vector database depends on your use case:
- For traditional text-based searches, a search engine is a proven and cost-effective solution.
- For AI-driven, context-aware knowledge retrieval, a vector database unlocks capabilities that traditional systems cannot achieve.
As organizations increasingly embrace AI, vector databases are becoming a cornerstone for modern knowledge search. However, the decision should align with your specific requirements, budget, and future plans.
By understanding these differences, you can make an informed decision and ensure your knowledge search capabilities are both effective and future-ready.
CloudKitect’s platform simplifies the provisioning of both secure Elasticsearch based search engines and vector databases, enabling organizations to leverage the best of both technologies with minimal effort. Using CloudKitect’s pre-built infrastructure-as-code components, you can set up a fully compliant, scalable Elasticsearch cluster or a high-performance vector database in aws in less than an hour. These components are designed to integrate seamlessly with your existing AWS environment, ensuring security best practices such as encryption, IAM policies, and network isolation are automatically applied. Whether you need a robust keyword search engine or an AI-powered semantic search solution, CloudKitect enables you to deploy these critical tools quickly, empowering your team to focus on delivering value without worrying about the complexities of infrastructure setup.
Talk to Our Cloud/AI Experts
Search Blog
About us
CloudKitect revolutionizes the way technology startups adopt cloud computing by providing innovative, secure, and cost-effective turnkey AI solution that fast-tracks the digital transformation. CloudKitect offers Cloud Architect as a Service.

