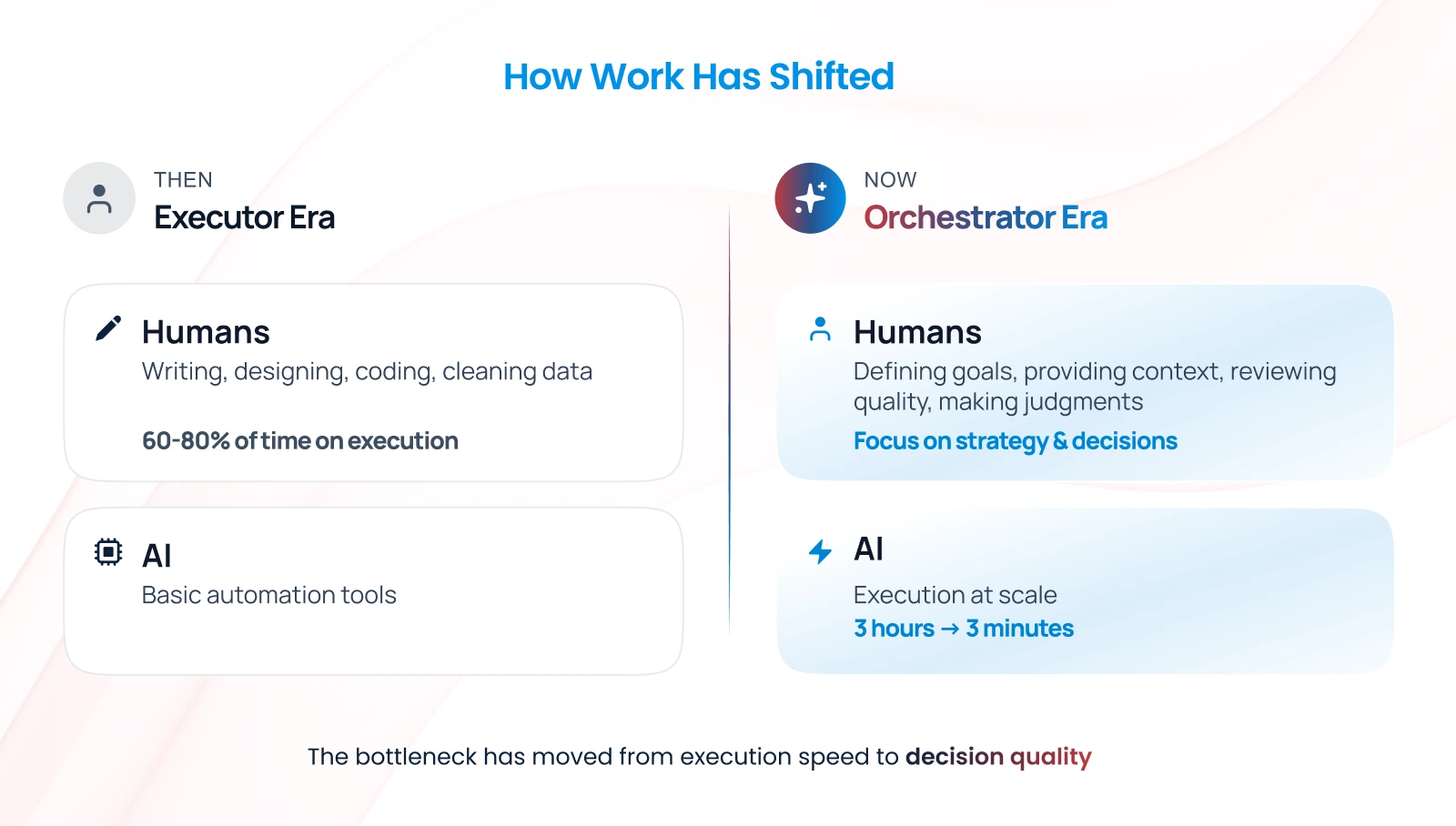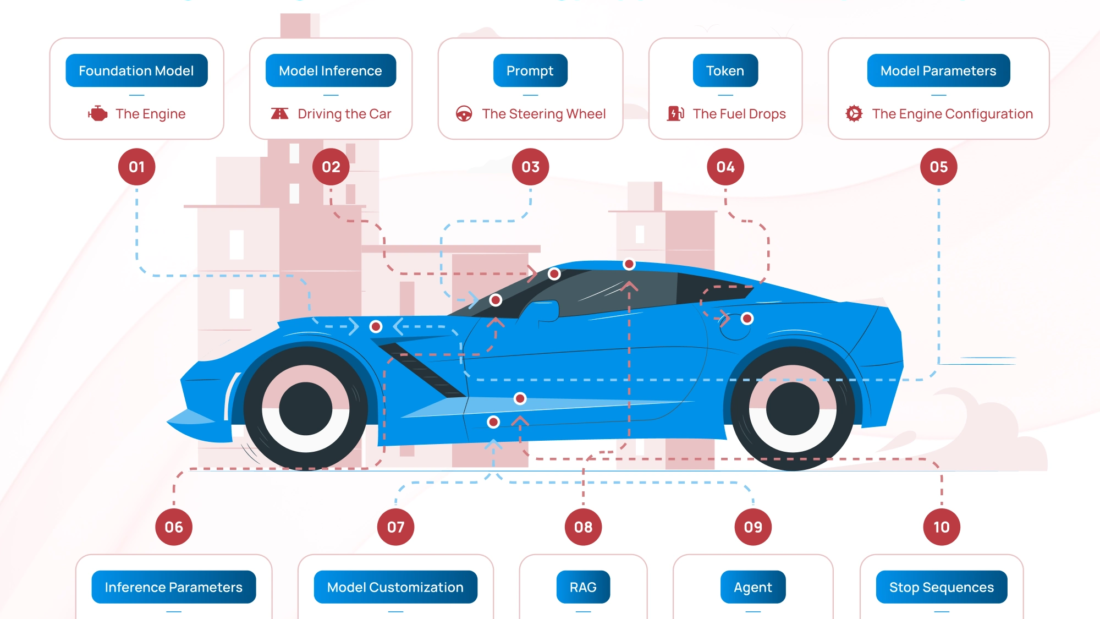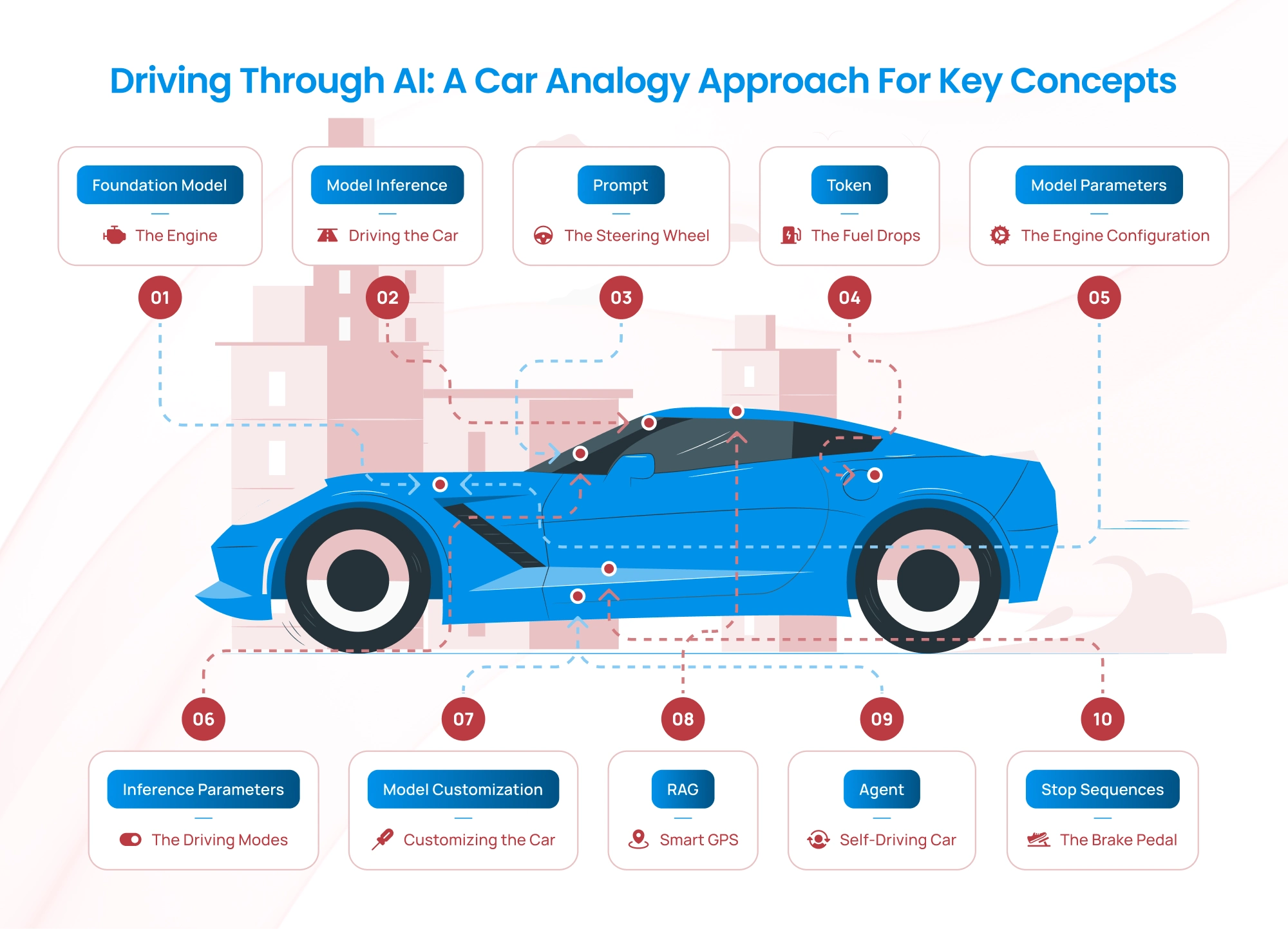

We’ve all been there. You’re working with an AI agent, explain your preferences, solve a problem together, and feel like you’re making real progress. Then you start a new conversation and… it’s like meeting a stranger. Everything resets. You’re back to square one.
At CloudKitect, we think a lot about why most AI agents still feel… forgetful.
- They can reason.
- They can use tools.
- They can act.
❎ But they don’t remember the way teams expect them to.
💡 That’s where episodic memory comes in.
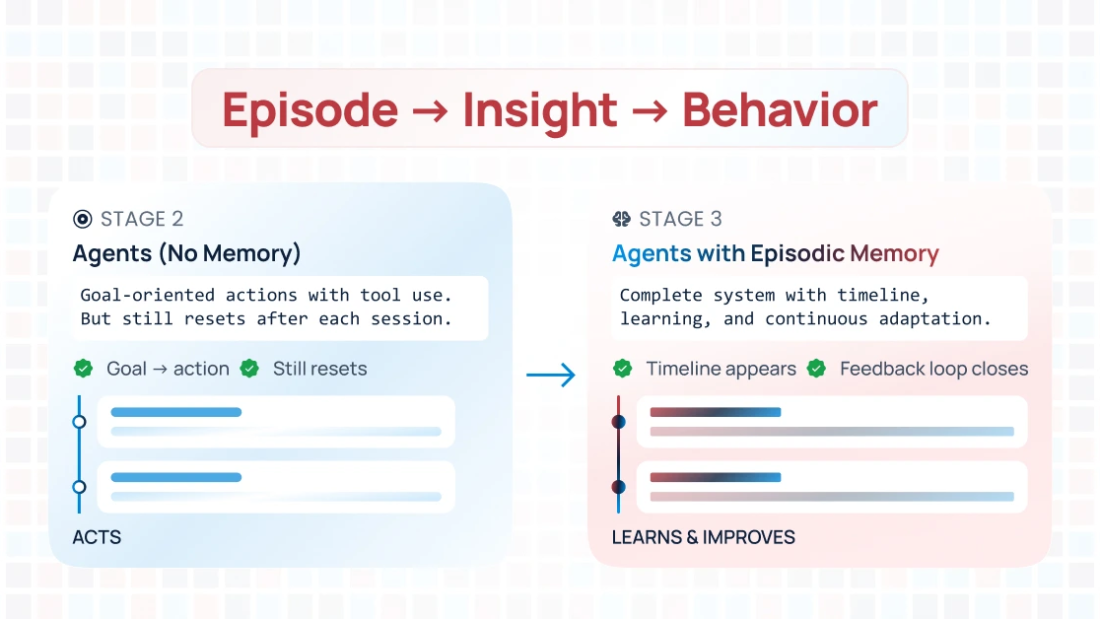
What Is Episodic Memory for AI Agents?
Episodic memory lets an agent remember past interactions as experiences, not just raw data.
Instead of storing:
“User said X”
The agent remembers:
“I tried X → it failed → Y worked better → user preferred Y”
This is the difference between:
- reacting to what someone says
- learning from experience to get better over time
Think of it like this: imagine if every time you called your doctor, they had no memory of your last visit, your medical history, or what treatments worked for you. They’d be competent, sure—but they’d have to start from scratch every single time. That’s how most AI agents work today.
With episodic memory, your doctor remembers not just facts about you, but the story of your care: what was tried, what worked, what didn’t, and why.
The Human Brain Connection
This isn’t just a clever engineering trick—it’s directly inspired by how human memory actually works.
Neuroscientists distinguish between several types of memory, but two are particularly relevant here:
Semantic memory is your knowledge of facts: Paris is the capital of France. Python is a programming language. A circle has 360 degrees.
Episodic memory is your memory of experiences: the time you debugged that gnarly race condition at 2am. The project where the client kept changing requirements. That meeting where Sarah’s suggestion actually solved everything.
When you’re good at your job, you’re not just drawing on facts—you’re drawing on a rich library of past experiences. You remember what worked, what failed, and crucially, the context around those successes and failures.
AI agents with only semantic memory are like professionals with amnesia. They know their field, but they can’t learn from their own history. They can’t improve based on what happened yesterday, last week, or five minutes ago.
Why This Matters for Agentic AI
Most agents today operate in a tight loop:
reason → act → respond
With episodic memory, that loop becomes:
reason → act → evaluate → remember → improve
That single addition changes everything.

Agents Stop Repeating Mistakes
Without episodic memory, an agent might suggest the same failed solution repeatedly. With it, the agent remembers:
“Last time I suggested Restaurant A for your anniversary, you said it was too loud—let me suggest somewhere quieter this time.”
Personalization Becomes Real
Instead of generic responses, agents adapt to your specific patterns. They learn your communication style, your preferences, your habits, your pet peeves.
Context Carries Forward
An agent can remember that “she prefers morning workouts” or “he’s allergic to shellfish” or “they’re saving up for a house.” These aren’t just facts—they’re learned patterns from past interactions.
Relationships Get Deeper
Just like human relationships deepen over time through shared experiences, an AI agent with episodic memory builds a genuine understanding of you. It becomes less like talking to a search engine and more like talking to someone who knows you.
Examples: Episodic Memory in Action
Example 1: Planning a Weekend
Without episodic memory
- You: “Help me plan something fun this weekend”
- Agent: “How about visiting a museum or trying a new restaurant?”
- You: “I don’t really like museums, and we went out to eat last weekend”
- Agent: Suggests alternatives
Next month
- You: “Weekend ideas?”
- Agent: “How about a museum?” ❌
With episodic memory
- You: “Help me plan something fun this weekend”
- Agent: “Last few times we talked, you enjoyed outdoor activities and cooking at home. The weather’s supposed to be nice—how about a hiking trail you haven’t tried yet, or I could suggest some new recipes?”
- You: “Perfect, let’s do the hiking trail”
- Agent: Remembers this preference for future suggestions ✅
Example 2: Travel Planning
Without episodic memory
- You: “Help me book a vacation”
- Agent: “Beach or mountains? Hotels or Airbnb? What’s your budget?”
- You: Explains all your preferences
Planning next year’s trip
- You: “Let’s plan another vacation”
- Agent: Asks all the same questions again ❌
With episodic memory
- You: “Let’s plan another vacation”
- Agent: “Based on your last three trips, you prefer mountains over beaches, Airbnbs with kitchens, and you travel in September to avoid crowds. Your budget is usually around $2,000. I’m seeing some great options in the Rockies. Should I focus there, or try something different this time?”
- You: “Actually, let’s try a beach this time for a change”
- Agent: “Got it! I’ll remember you’re open to beaches now, and I’ll still prioritize Airbnbs and September timing.”
- Adapts and learns ✅
CloudKitect’s Journey: Listening to Our Customers
This isn’t theoretical for us. We introduced episodic memory to CloudKitect based directly on customer requests.
Our users were telling us:
“Your AI helps us manage complex technical systems. But every time we start a new conversation, we have to re-explain everything about how our team works, what we’ve tried before, what matters to us.”
They wanted an AI that remembered their journey.
So we built it.
Now, when CloudKitect’s AI agent works with your team:
- It remembers your team’s communication patterns and preferences
- It learns from past successes and failures
- It recalls decisions you’ve made and why you made them
- It understands your priorities and adapts over time
The result? Teams move faster. Conversations feel natural. And the AI genuinely becomes smarter over time—not just in general, but specifically for your needs.
The Technical Challenge (And Why It’s Worth It)
Building episodic memory isn’t trivial. It requires:
- Efficient storage and retrieval of experience graphs
- Mechanisms to evaluate which memories are relevant to current situations
- Systems to update and refine memories as new information comes in
- Privacy and security controls around sensitive information
But the payoff is enormous.
The difference between an agent with and without episodic memory is the difference between talking to a helpful stranger every time versus building a relationship with someone who actually knows you.
What This Means for the Future
We’re still in the early days. As episodic memory systems mature, we’ll see AI agents that:
- Build genuinely deep understanding of individual preferences
- Remember years of interactions and learn from them
- Adapt not just to what you say, but to how you live
- Become trusted advisors rather than one-off tools
The vision isn’t AI that replaces human relationships—it’s AI that learns alongside you, accumulating wisdom from shared experiences.
The Bottom Line
Episodic memory transforms AI agents from powerful but forgetful tools into genuine learning partners. They don’t just respond—they remember, adapt, and improve.
It’s the difference between:
- A taxi driver who gets you where you need to go
- Your regular driver who knows you take the scenic route, prefer quiet conversation, and always stop for coffee on Tuesday mornings
At CloudKitect, we’re excited to be part of this evolution. Because when AI agents can truly learn from experience, they don’t just help you once—they grow with you.
And that changes everything.
Interested in seeing episodic memory in action?
CloudKitect’s AI-powered platform now includes episodic memory capabilities, helping teams work smarter by learning from every interaction.
Search Blog
About us
CloudKitect revolutionizes the way technology startups adopt cloud computing by providing innovative, secure, and cost-effective turnkey AI solution that fast-tracks the digital transformation. CloudKitect offers Cloud Architect as a Service.
Related Resources

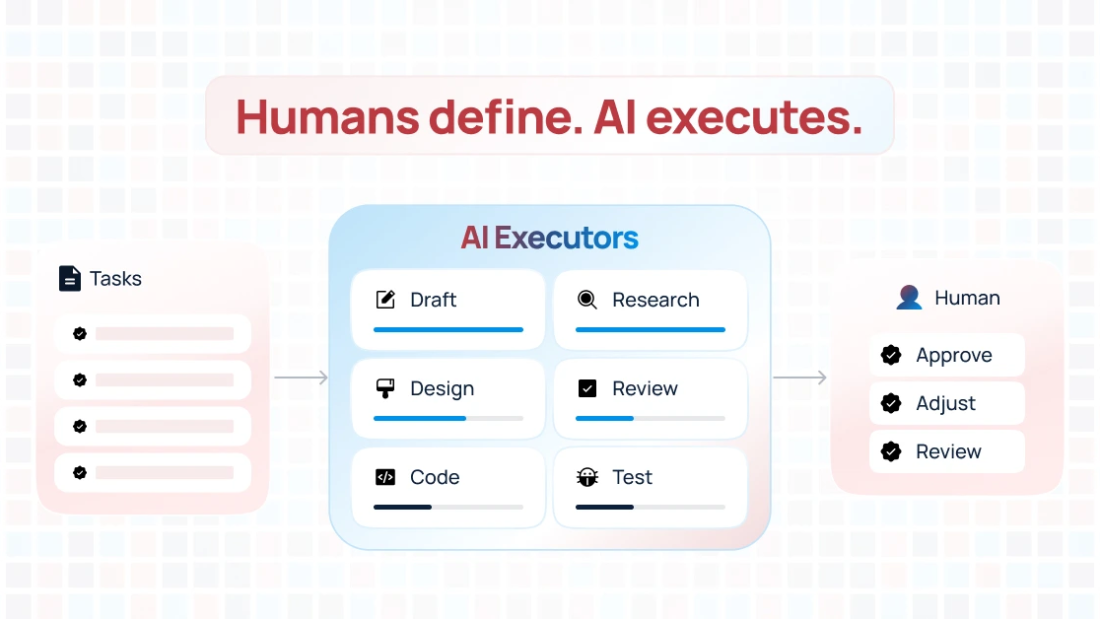
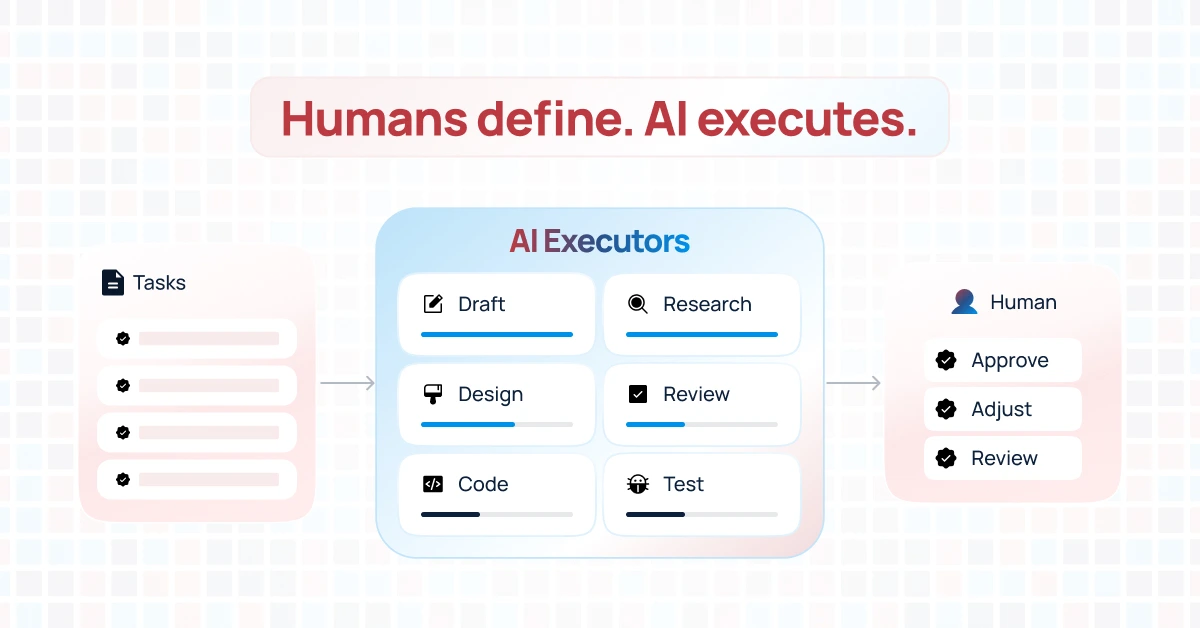
Episodic Memory: The Missing Piece That Makes AI Agents Actually Learn

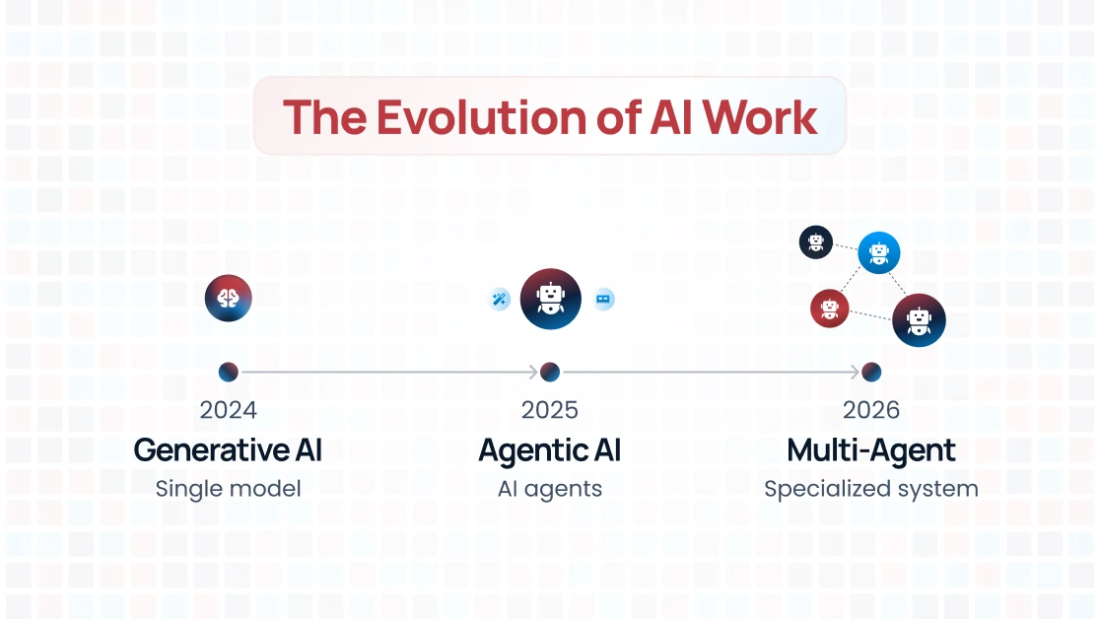
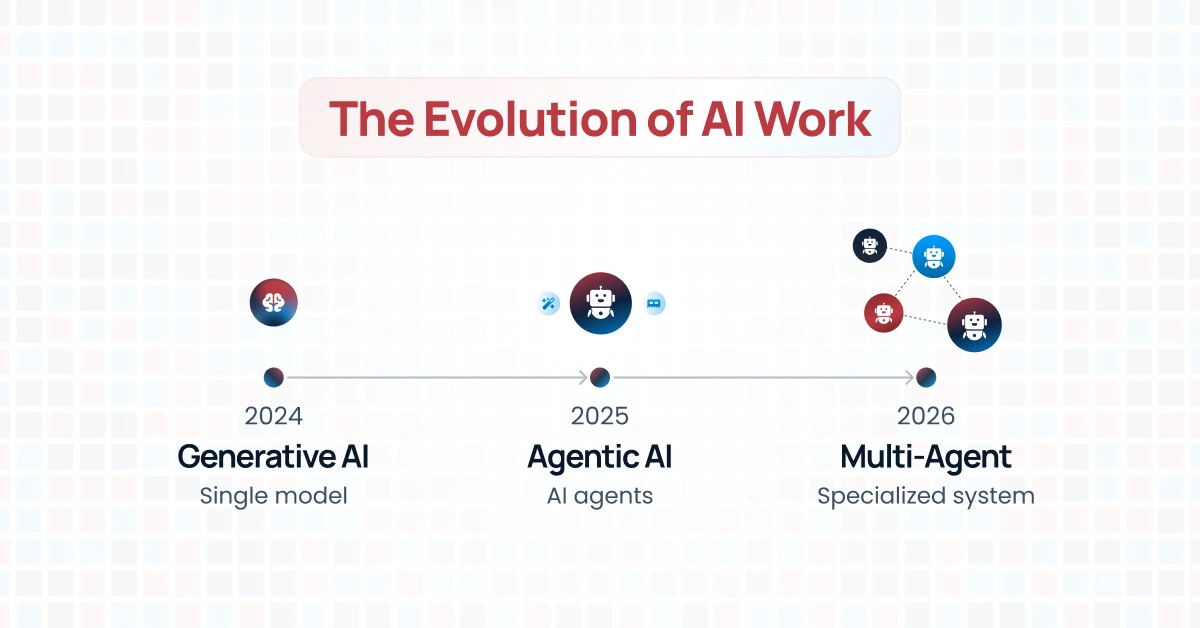
Evolution of AI [2024-2026]: From Generative Breakthroughs to Multi-Agent Orchestration