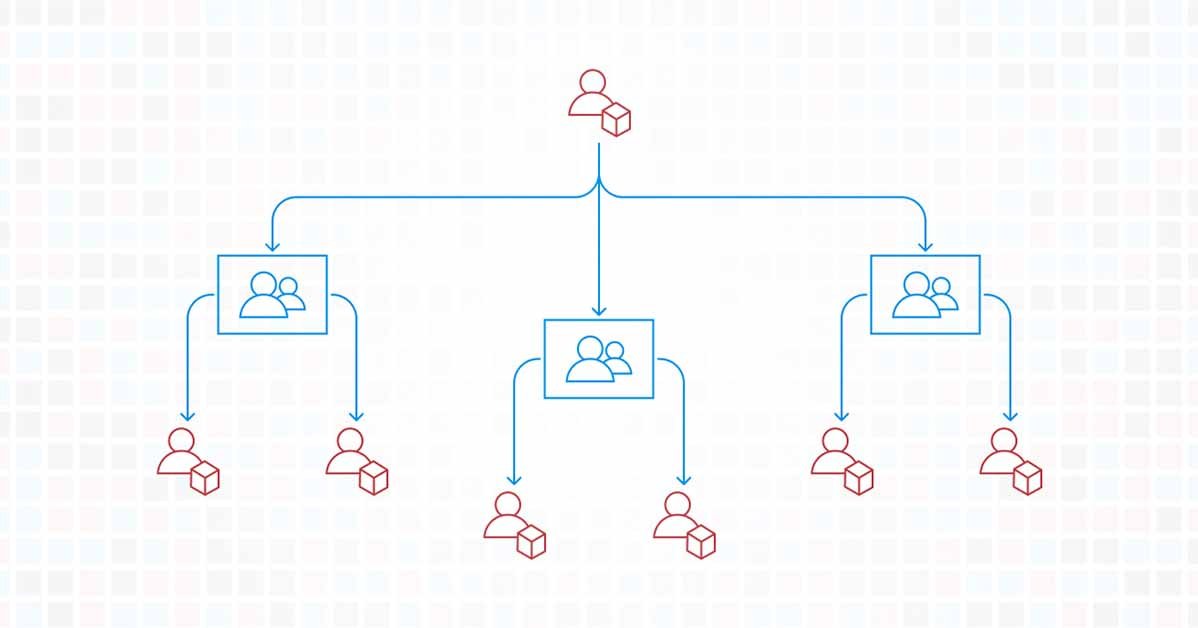
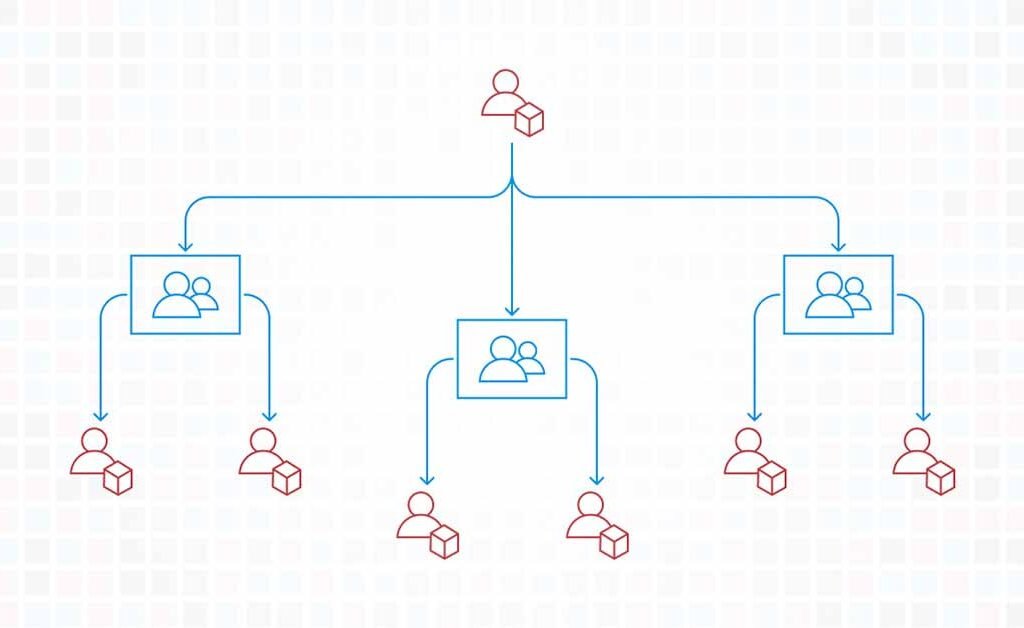
Amazon Web Services (AWS) provides an array of resources and services that have revolutionized how organizations approach their IT infrastructure. However, building enterprise grade cloud infrastructure is complex and a critical facet of simplifying these complex infrastructures is effective account structuring. In this context, CloudKitect always recommends their customer to employ a multi-account strategy that will provide an advanced layer of security, easier management, and efficient cost-tracking.
Enhanced Security
The multi-account strategy is crucial for maintaining the security and integrity of AWS resources. By segregating resources into distinct accounts, a boundary is created, preventing security incidents from impacting resources across the whole organization. In case of a security breach, the issue is confined to the compromised account, which significantly reduces the potential damage.
Moreover, each AWS account has distinct Identity and Access Management (IAM) policies, allowing for granular control over access to resources. This limits the scope of privileges that any individual user or service has, further enhancing the security within each account.
Simplified Management and Operational Resilience
A multi-account architecture allows for clear separation of concerns. Each account can be designated to a particular department, project, or environment (development, staging, production). This can drastically simplify resource management, as resources pertinent to a specific department or project are easily identifiable and manageable.
Operational resilience is another key benefit. For instance, if one account’s resources hit a service limit, it will not affect the operation of resources in other accounts. This isolation aids in maintaining business continuity even if an issue arises in a particular department or project.
Efficient Cost Allocation and Tracking
An AWS multi-account strategy can play a vital role in cost management. By breaking down AWS usage per account, organizations can better track and allocate costs. Each account can be assigned to a specific cost center or project, thereby enabling accurate cost attribution. This enhances the transparency of cloud expenditure, making it easier for organizations to understand where their money is being spent and which projects or departments are incurring those costs.
Compliance and Auditing
With a multi-account strategy, compliance and auditing become more manageable tasks. Each account has its own set of CloudTrail logs, simplifying the auditing process. It becomes much easier to track actions and changes in an environment specific to a project or a department. If compliance needs to be ensured across a certain department, having a separate AWS account for it means that auditors only need to focus on that specific account rather than the whole organization.
Greater Control over Service Limits
Each AWS account comes with its own service limits, which provides an additional layer of control and prevents any one project or department from using all of an organization’s resources. By employing a multi-account strategy, you’re able to ensure that one department’s heavy usage won’t impact other departments’ operations.
Conclusion
In conclusion, a multi-account strategy is a powerful tool when operating in the AWS cloud. By offering enhanced security, simplified management, efficient cost tracking, easier compliance and auditing, and better control over service limits, it significantly simplifies and strengthens the cloud management for organizations of all sizes. This allows businesses to take full advantage of the flexibility and power of the AWS cloud, while maintaining control and visibility over their resources. Therefore, a multi-account strategy should be a key part of any organization’s AWS planning and management.
CloudKitect has developed advanced tooling to facilitate the effortless adoption of a multi-account strategy, incorporating all best practice recommendations from AWS. Reach out to us today for a thorough evaluation of your Cloud Strategy and let us assist you in embracing cloud technology in the most effective manner.
Talk to Our Cloud/AI Experts
Search Blog
About us
CloudKitect revolutionizes the way technology startups adopt cloud computing by providing innovative, secure, and cost-effective turnkey solution that fast-tracks the digital transformation. CloudKitect offers Cloud Architect as a Service.
Related Resources
Generative AI Project Lifecycle: A Comprehensive Guide

Unlocking Data Insights: Chat with Your Data | PDF and Beyond