
Choosing Between Retrieval-Augmented Generation (RAG) and Fine-Tuning for LLMs: A Detailed Comparison
- Blog
- Muhammad Tahir
Using Large Language Models, Generative AI has revolutionized how businesses and developers tackle problems that involve natural language processing. Two popular strategies for tailoring these models to specific needs are Retrieval-Augmented Generation (RAG) and Fine-Tuning. Both approaches have distinct advantages and limitations, making the choice between them highly context-dependent.
This blog explores when to use RAG versus Fine-Tuning by diving deep into their core mechanisms, pros and cons, and practical use cases.
Understanding RAG and Fine-Tuning
Retrieval-Augmented Generation (RAG)
RAG combines a pre-trained LLM with an external knowledge base. Instead of relying solely on the model’s internal knowledge, RAG retrieves relevant documents or data from an external source (e.g., a database or document repository) and integrates it into the model’s response generation.
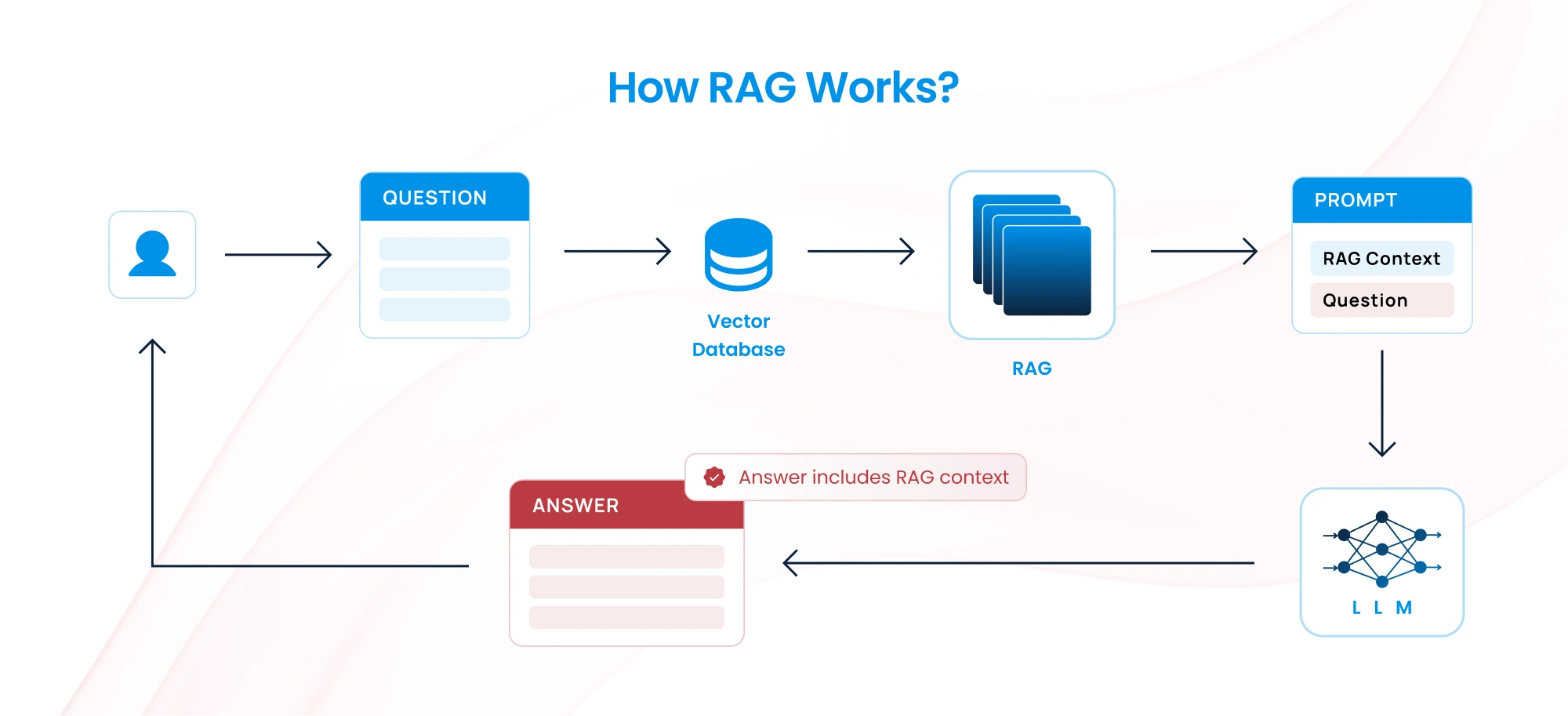
How it works:
- A retrieval system (e.g., vector database) fetches relevant information based on the user query.
- The fetched information is passed into the model as part of the input context.
- The LLM generates a response using both the input query and the retrieved context.
Key technologies: Vector embeddings, databases like OpenSearch, Pinecone or Weaviate, and LLMs. To read more about Vector database check our blog post on Harnessing the power of OpenSearch as Vector Database
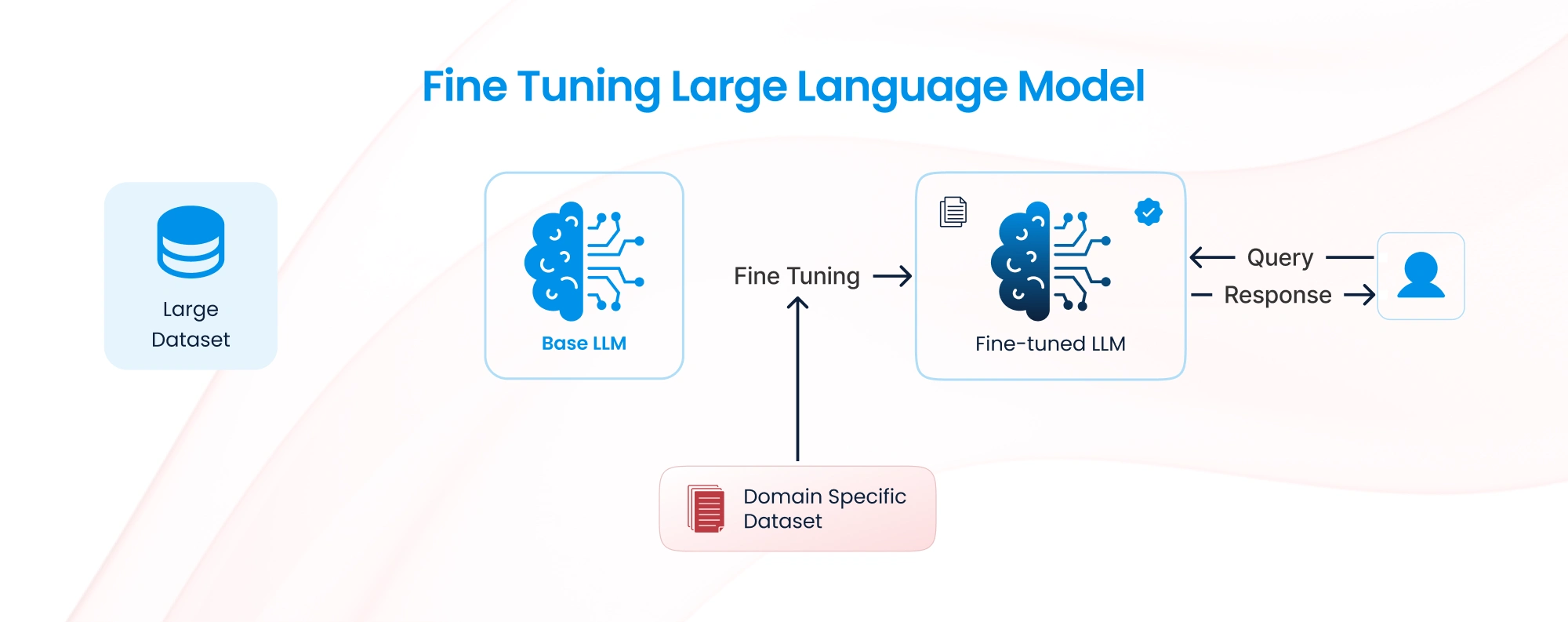
Fine-Tuning
Fine-tuning involves retraining the LLM on a specific dataset to adapt it to a particular domain, tone, or style. During this process, the model adjusts its parameters to encode the specific patterns in the provided data.
To understand fine tuning better checkout our blog post on How to Assess the Performance of Fine-tuned LLMs
Detailed Comparison: RAG vs Fine-Tuning
How it works:
A domain-specific dataset is prepared and pre-processed.
The model is trained further on this dataset using supervised learning.
The resulting model specializes in the domain or task represented by the dataset.
Key technologies: LLM fine-tuning frameworks like Hugging Face’s transformers, OpenAI’s fine-tuning APIs, and datasets in JSONL format.
1. Knowledge Adaptability
RAG: Ideal when the domain knowledge is large, dynamic, or constantly updated (e.g., legal regulations, financial reports).
- Example: A legal assistant fetching the latest rulings or case laws from a database.
Fine-Tuning: Best for scenarios where the knowledge is stable and well-defined (e.g., customer service scripts, FAQs).
- Example: A chatbot trained on a company’s fixed product catalog and support information.
2. Maintenance and Updates
RAG: Easier to maintain. The knowledge base can be updated without retraining the model.
- Pro: Reduces downtime and cost for updates.
- Con: Requires a robust and efficient retrieval system.
Fine-Tuning: Requires retraining the model every time the knowledge changes, which can be time-consuming and costly.
- Pro: Encodes knowledge directly into the model.
- Con: Inefficient for rapidly changing data.
3. Cost and Resource Implications
RAG: Generally cheaper in the long term since it avoids retraining the model. Storage and retrieval system costs can scale, though. For a detailed analysis on build vs buy a RAG system check our blog on Time and Cost Analysis of Building vs Buying AI solutions.
- Example: SaaS companies integrating AI with customer databases.
Fine-Tuning: High upfront costs due to dataset preparation and training but low per-query costs after deployment.
- Example: A fine-tuned LLM for summarizing medical documents.
4. Query Response Time
RAG: Slower, as it involves retrieving data and processing additional input for each query.
- Use Case: Applications where accuracy and relevance outweigh speed.
Fine-Tuning: Faster, as it doesn’t rely on external lookups.
- Use Case: High-throughput, low-latency scenarios.
5. Customization and Control
RAG: Allows flexible responses by incorporating dynamic external data but may lack a consistent style or tone.
- Pro: Highly adaptable for new queries.
- Con: Depends on the quality of the retrieval system.
Fine-Tuning: Offers precise control over the model’s behavior, tone, and style since it learns directly from the dataset.
- Pro: Better for tasks like brand voice consistency.
- Con: Less adaptable to queries outside its training data.
6. Scalability
RAG: Scales well across multiple domains as you can plug in new databases or knowledge bases.
- Example: A multi-industry AI tool switching between retail and healthcare data.
Fine-Tuning: Limited scalability since each new domain or task requires separate fine-tuning.
- Example: Training distinct models for each use case.
7. Privacy and Compliance
RAG: Sensitive data can be stored and retrieved securely without embedding it into the model.
- Con: Requires robust data security measures for the external knowledge base.
Fine-Tuning: Embeds knowledge directly into the model, which may raise concerns if the data contains sensitive information.
- Pro: Easier to deploy as a self-contained solution.
When to Use RAG
- Dynamic Knowledge: Industries like law, finance, or healthcare with rapidly changing information.
- Low Latency Not Critical: Applications where accuracy and relevance are more important than speed.
- Multi-Domain Applications: Tools that require switching contexts without training multiple models.
- Cost-Sensitive Environments: Teams looking to minimize training and updating expenses.
When to Use Fine-Tuning
- Stable Knowledge: Domains where information rarely changes (e.g., a fixed onboarding guide).
- Consistency in Responses: Tasks requiring precise tone and behavior (e.g., branded customer support).
- Low-Latency Applications: Scenarios where speed is critical (e.g., real-time assistance).
- Resource Availability: Teams with the budget and expertise to manage fine-tuning processes.
Combining RAG and Fine-Tuning
In some cases, the best solution might involve combining RAG and fine-tuning:
- Example: Fine-tune an LLM for general domain understanding and tone, then integrate RAG for dynamic, domain-specific retrieval.
- Hybrid Use Case: A customer support bot trained on a product catalog (fine-tuning) but capable of fetching updates on return policies from a database (RAG).
Conclusion
The choice between Retrieval-Augmented Generation and Fine-Tuning boils down to your project’s unique requirements:
-
- Choose RAG for flexibility, dynamic data, and cost efficiency.
- Opt for Fine-Tuning for precision, stable data, and consistent tone.
Understanding the trade-offs and leveraging them effectively will ensure you deliver optimal AI solutions for your specific needs.
Not sure what would work best for your use case? We are here to help!
Talk to Our Cloud/AI Experts
Search Blog
About us
CloudKitect revolutionizes the way technology startups adopt cloud computing by providing innovative, secure, and cost-effective turnkey AI solution that fast-tracks the digital transformation. CloudKitect offers Cloud Architect as a Service.

