
How to Maximize Data Retrieval Efficiency: Leveraging Vector Databases with Advanced Techniques
- Blog
- Muhammad Tahir
In the age of big data and artificial intelligence, retrieving relevant information efficiently is more critical than ever. Traditional databases often fall short in handling complex queries, especially when the search involves semantic understanding, contextual relevance, or nuanced interpretations. This is where vector databases come into play. Vector databases leverage advanced techniques like semantic similarity, maximum marginal relevance (MMR), and LLM (Large Language Model) aided retrieval to provide more accurate and context-aware results.
In this blog post, we’ll explore these strategies and more, using practical examples to illustrate how each method enhances vector database retrieval.
What is a Vector Database?
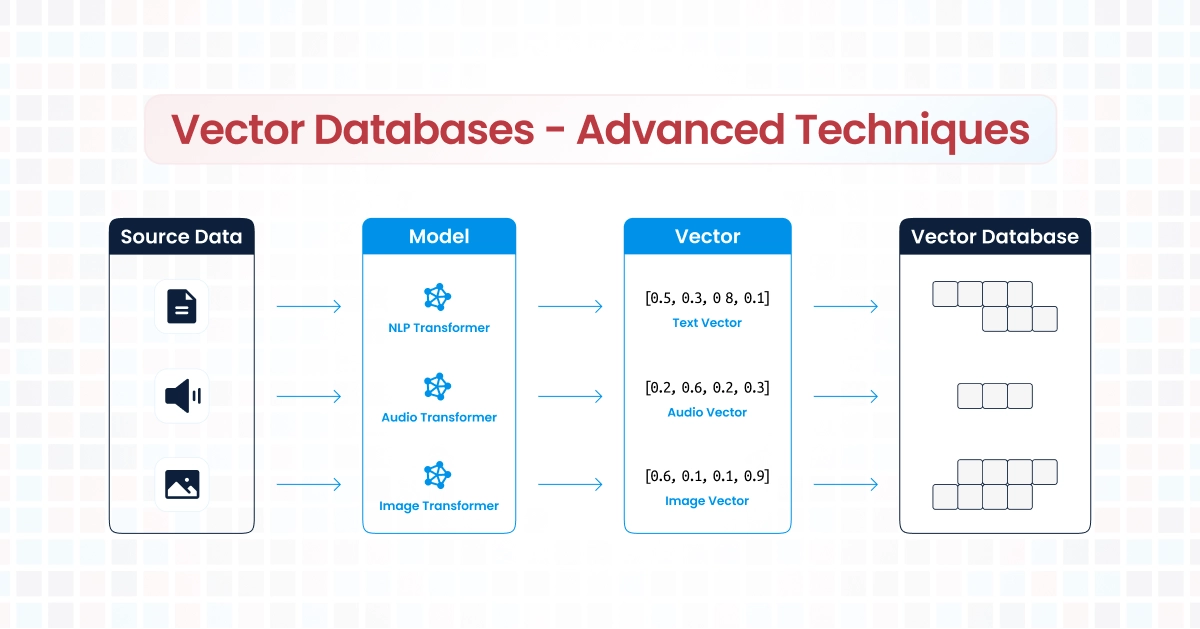
A vector database is a type of database designed to store and manage vector embeddings—numerical representations of data points (e.g., text, images, audio) in a high-dimensional space. These vectors enable advanced retrieval techniques based on similarity, context, and relevance, making vector databases ideal for applications like natural language processing (NLP), image recognition, and recommendation systems. One such database is Open Search from aws, click here if you want to learn about OpenSearch as a vector database.
Key Strategies in Vector Database Retrieval
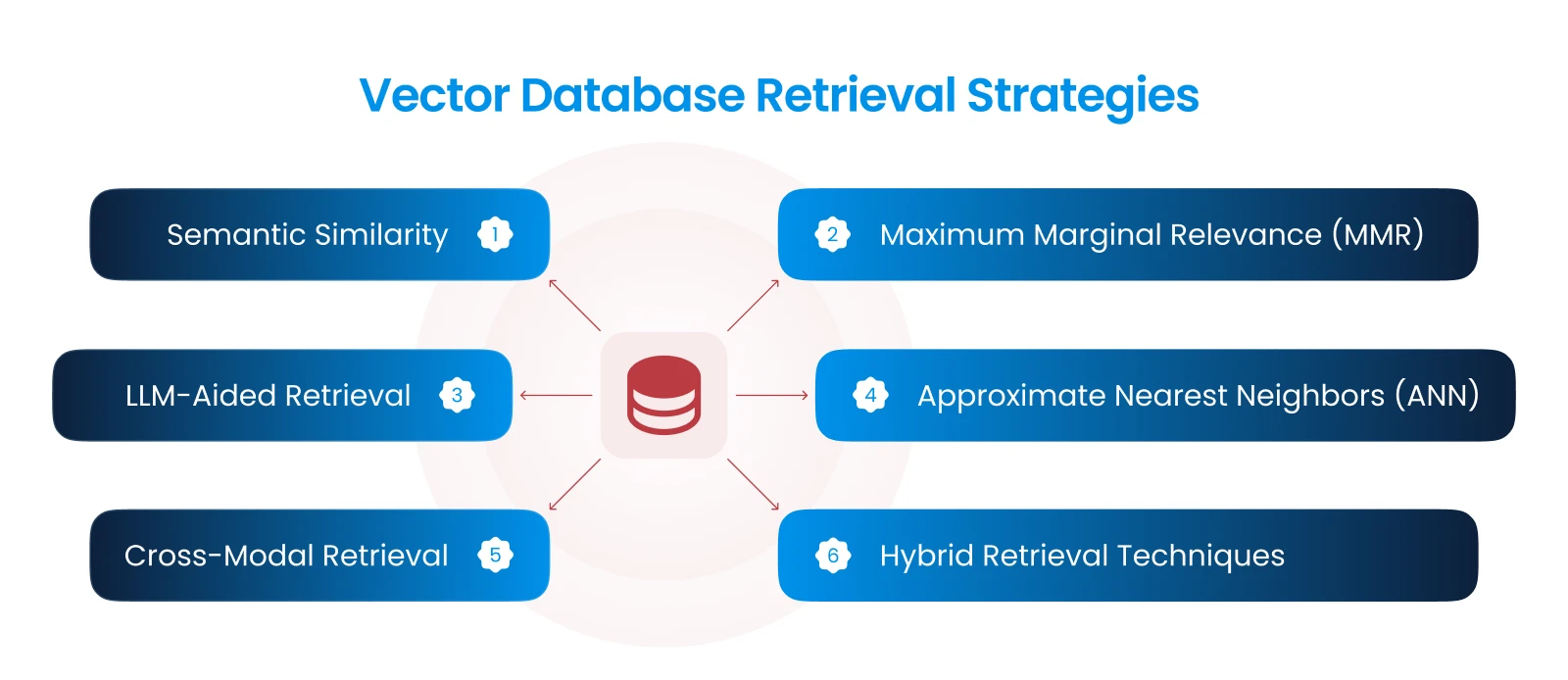
1 - Semantic Similarity
Semantic similarity measures how closely related two data points are in meaning or context. In vector databases, this is typically achieved by comparing the distance between vectors in the embedding space.
- Cosine Similarity: One of the most common methods, cosine similarity, calculates the cosine of the angle between two vectors. The closer the angle is to zero, the more similar the vectors (and hence, the data points) are.
- Euclidean Distance: This method measures the straight-line distance between two vectors in space. It’s a more intuitive approach but can be sensitive to the magnitude of the vectors.
Example: Suppose you have a vector database of product descriptions. A user searches for “wireless earbuds.” The database calculates the semantic similarity between the search query vector and the product description vectors. Products with descriptions like “Bluetooth headphones” or “true wireless earbuds” will likely have high similarity scores and be retrieved as relevant results.
2 - Maximum Marginal Relevance (MMR)
Maximum Marginal Relevance is a technique that balances relevance and diversity in retrieval results. It’s particularly useful in situations where you want to avoid redundancy and ensure that the results cover a broad spectrum of relevant information.
- MMR Formula: MMR is calculated as a trade-off between relevance (how closely a result matches the query) and diversity (how different a result is from the already selected results). The formula typically looks like:
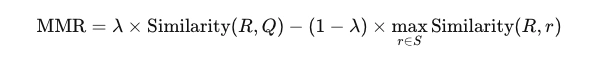
where R is a candidate result, Q is the query, S is the set of already selected results, and lambda is a parameter that controls the balance between relevance and diversity.
Example: Consider a news aggregator that retrieves articles based on a user’s search. Without MMR, the top results might include multiple articles from the same source or covering the same angle of a story. By applying MMR, the aggregator ensures that the top results include diverse perspectives, preventing redundancy and providing a broader view of the topic.
3 - LLM-Aided Retrieval
Large Language Models (LLMs) like GPT-3 or BERT can significantly enhance retrieval by understanding context, generating queries, or even re-ranking results based on deeper semantic understanding.
- Contextual Query Expansion: LLMs can expand a user’s query by understanding the underlying intent and adding related terms or phrases. This helps in retrieving more relevant results.
- Re-ranking with LLMs: After an initial retrieval using traditional methods, LLMs can re-rank the results by evaluating them based on a deeper understanding of the context and semantics.
Example: Imagine a legal database where a user searches for cases related to “contract breaches.” An LLM could expand the query to include related legal terms like “breach of contract,” “contract violation,” or “non-performance.” The model could also re-rank the results to prioritize cases that are more relevant to the user’s specific situation, such as those involving similar industries or contract types.
4 - Approximate Nearest Neighbors (ANN)
In large-scale vector databases, finding the exact nearest neighbors for a query vector can be computationally expensive. ANN algorithms provide a solution by quickly finding approximate neighbors that are close enough to the query vector.
- FAISS (Facebook AI Similarity Search): One popular library for ANN is FAISS, which efficiently handles large-scale vector searches by using indexing techniques like clustering and quantization.
- HNSW (Hierarchical Navigable Small World): Another method, HNSW, constructs a graph where nodes represent vectors, and edges connect similar nodes. This graph is navigated to find approximate neighbors efficiently.
Example: In a recommendation system for streaming services, when a user watches a movie, the system retrieves similar movies using vector embeddings. ANN methods like FAISS quickly find movies that are similar in genre, tone, or theme, providing recommendations that align with the user’s tastes without the computational burden of exact nearest neighbor searches.
5 - Cross-Modal Retrieval
Cross-modal retrieval involves retrieving results across different types of data, such as text, images, or audio. This requires creating embeddings that can be compared across these modalities.
- Unified Embedding Space: The key to cross-modal retrieval is mapping different data types into a unified embedding space where similarities can be directly compared.
- Multimodal Transformers: These models, trained on datasets containing multiple modalities, can create embeddings that capture relationships across different types of data.
Example: A user uploads an image of a landmark to a travel website’s search bar. The website’s cross-modal retrieval system converts the image into a vector and retrieves relevant text-based travel guides, blog posts, or tour listings that describe the landmark, even though the original query was an image.
6 - Hybrid Retrieval Techniques
Hybrid retrieval combines multiple strategies to improve the overall effectiveness of the search. For example, a system might use semantic similarity to narrow down the results, then apply MMR to ensure diversity, and finally use an LLM to refine and rank the final list.
Example: A customer support chatbot might first retrieve a list of potential solutions using semantic similarity, then apply MMR to ensure the solutions cover different potential issues. Finally, it might use an LLM to rank these solutions based on their relevance to the customer’s specific query, ensuring that the most likely solution is presented first.
Implementing Vector Database Retrieval
To implement these strategies in practice, organizations can use various tools and frameworks:
- FAISS: For efficient similarity searches using ANN.
- Hugging Face Transformers: For LLM-based query expansion and re-ranking.
- ScaNN (Scalable Nearest Neighbors): Another option for fast nearest neighbor search, particularly in large datasets.
- OpenAI API: For integrating advanced LLMs like GPT-3 into retrieval workflows.
Conclusion
Vector database retrieval is a powerful approach to handling complex queries in modern applications, from recommendation systems to search engines. By leveraging strategies like semantic similarity, MMR, LLM-aided retrieval, ANN, cross-modal retrieval, and hybrid techniques, organizations can significantly enhance the relevance and quality of their search results. As AI continues to evolve, these methods will become increasingly vital in unlocking the full potential of data stored in vector databases, providing users with more accurate, diverse, and contextually relevant information.
Talk to Our Cloud/AI Experts
Search Blog
About us
CloudKitect revolutionizes the way technology startups adopt cloud computing by providing innovative, secure, and cost-effective turnkey AI solution that fast-tracks the digital transformation. CloudKitect offers Cloud Architect as a Service.

