
Understanding Quantization in Machine Learning and Its Importance in Model Training
- Blog
- Muhammad Tahir
Machine learning has revolutionized numerous fields, from healthcare to finance, by enabling computers to learn from data and make intelligent decisions. However, the growing complexity and size of machine learning models have brought about new challenges, particularly in terms of computational efficiency and resource consumption. One technique that has gained significant traction in addressing these challenges is quantization. In this blog, we will explore what quantization is, how it works, and why it is crucial for training machine learning models. click here, If you’re interested in learning generative AI project lifecycle.
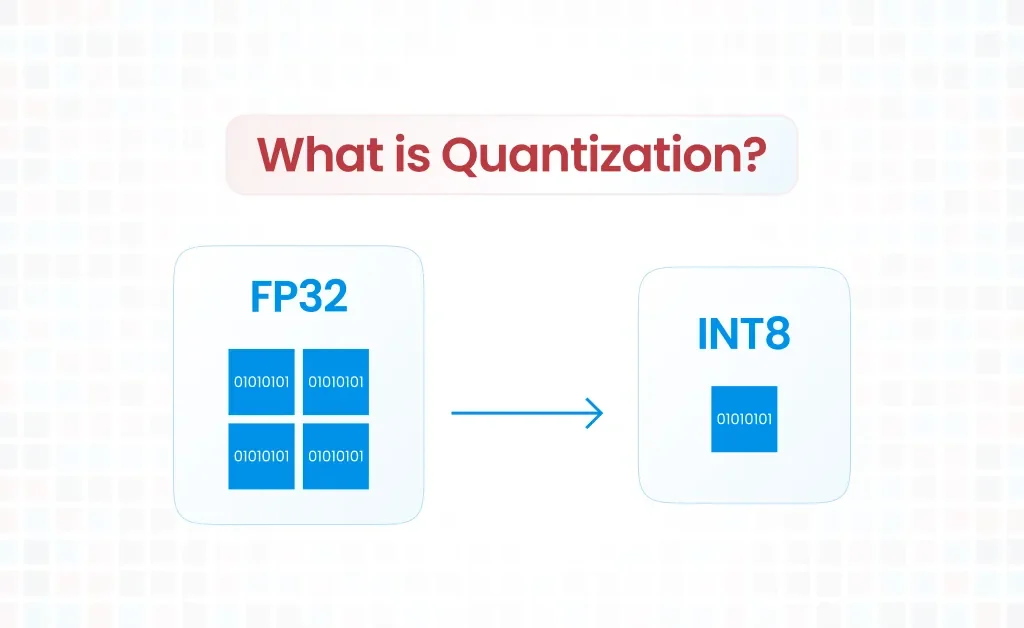
What is Quantization?
Quantization in the context of machine learning refers to the process of reducing the precision of the numbers used to represent a model’s parameters (weights and biases) and activations. Typically, machine learning models use 32-bit floating-point numbers (FP32) to perform computations. Quantization reduces this precision to lower-bit representations, such as 16-bit floating-point (FP16), 8-bit integers (INT8), or even lower.
The primary goal of quantization is to make models more efficient in terms of both speed and memory usage, without significantly compromising their performance. By using fewer bits to represent numbers, quantized models require less memory and can perform computations faster, which is particularly beneficial for deploying models on resource-constrained devices like smartphones, embedded systems, and edge devices.
Types of Quantization
There are several approaches to quantization, each with its own advantages and trade-offs:

- Post-Training Quantization: This approach involves training the model using high-precision numbers (e.g., FP32) and then converting it to a lower precision after training. It is a straightforward method but might lead to a slight degradation in model accuracy.
- Quantization-Aware Training: In this method, the model is trained with quantization in mind. During training, the model simulates the effects of quantization, which allows it to adapt and maintain higher accuracy when the final quantization is applied. This approach typically yields better results than post-training quantization.
- Dynamic Quantization: This method quantizes weights and activations dynamically during inference, rather than having a fixed precision. It provides a balance between computational efficiency and model accuracy.
- Static Quantization: Both weights and activations are quantized to a fixed precision before inference. This method requires calibration with representative data to achieve good performance.
The primary goal of quantization is to make models more efficient in terms of both speed and memory usage, without significantly compromising their performance. By using fewer bits to represent numbers, quantized models require less memory and can perform computations faster, which is particularly beneficial for deploying models on resource-constrained devices like smartphones, embedded systems, and edge devices.

Why Quantization is Needed for Training Models
Quantization offers several key benefits that address the challenges associated with training and deploying machine learning models:

- Reduced Memory Footprint: By using lower-bit representations, quantized models require significantly less memory. This reduction is crucial for deploying models on devices with limited memory capacity, such as IoT devices and mobile phones.
- Faster Computation: Lower-precision computations are faster and require less power than their higher-precision counterparts. This speedup is essential for real-time applications, where quick inference is critical.
- Lower Power Consumption: Quantized models are more energy-efficient, making them ideal for battery-powered devices. This efficiency is especially important for applications like autonomous vehicles and wearable technology.
- Cost-Effective Scaling: Quantization allows for the deployment of large-scale models on cloud infrastructure more cost-effectively. Reduced memory and computational requirements mean that more instances of a model can be run on the same hardware, lowering operational costs.
- Maintained Model Performance: When done correctly, quantization can maintain or even enhance the performance of a model. Techniques like quantization-aware training ensure that the model adapts to lower precision during training, preserving its accuracy.
Example of Quantization: Reducing the Precision of Neural Network Weights:
Imagine you have a neural network trained to recognize images of animals. This network has millions of parameters (weights) that help it make decisions. Typically, these weights are represented as 32-bit floating-point numbers, which offer high precision but require significant memory and computational power to store and process.
Quantization Process:
To make the model more efficient, you decide to apply quantization. This process involves reducing the precision of the weights from 32-bit floating-point numbers to 8-bit integers. By doing so, you reduce the memory footprint of the model and speed up computations, as operations with 8-bit integers are faster and less resource-intensive than those with 32-bit floats.
Example in Practice:
- Original Weight:
Suppose a weight in the neural network has a 32-bit floating-point value of 0.789654321. - Quantized Weight:
After quantization, this weight might be approximated to an 8-bit integer value, say 0.79 (depending on the quantization method used, such as rounding, truncation, or other techniques). - Model Performance:
The quantized model is now faster and requires less memory. The reduction in precision might slightly decrease the model’s accuracy, but in many cases, this trade-off is minimal and acceptable, especially when the gain in efficiency is significant. - Benefits:
– Reduced Memory Usage:
The model now requires less storage, making it more suitable for deployment on devices with limited memory, such as mobile phones or IoT devices.
– Faster Computation:
The model can process data faster, which is crucial in real-time applications like autonomous driving or video streaming.
Conclusion
Quantization is a powerful technique in the arsenal of machine learning practitioners, offering a way to tackle the challenges of computational efficiency, memory usage, and power consumption. By reducing the precision of numbers used in model parameters and activations, quantization enables the deployment of sophisticated machine learning models on a wide range of devices, from powerful cloud servers to constrained edge devices.
As machine learning continues to evolve and become more ubiquitous, the importance of efficient model training and deployment will only grow. Quantization stands out as a vital tool in achieving these goals, ensuring that we can harness the full potential of machine learning in an efficient and scalable manner.
Talk to Our Cloud/AI Experts
Search Blog
About us
CloudKitect revolutionizes the way technology startups adopt cloud computing by providing innovative, secure, and cost-effective turnkey AI solution that fast-tracks the digital transformation. CloudKitect offers Cloud Architect as a Service.

