
We’re in the midst of an AI gold rush. Every organization is racing to implement AI—chatbots, predictive analytics, automation platforms. Boards are asking “What’s our AI strategy?” Budgets are being allocated. Vendors are being evaluated.
But here’s the uncomfortable truth most organizations are ignoring:
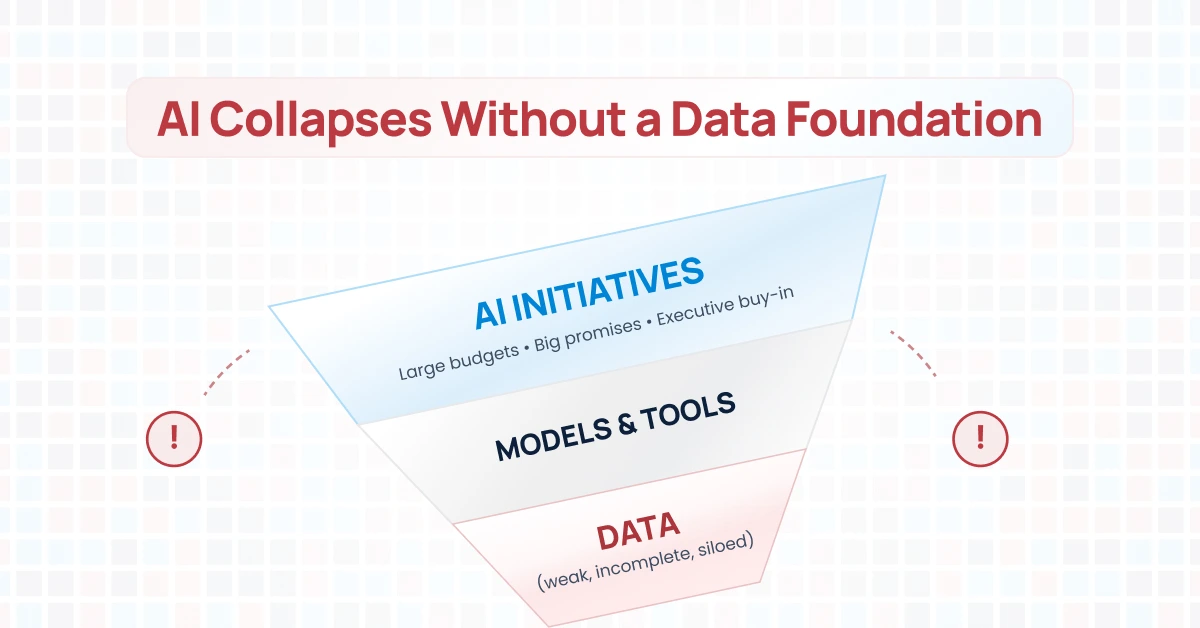
Your AI initiative will fail not because of the technology, but because of your data.
The Seductive Lie of "AI-Ready"
The pitch is intoxicating: “Just plug our AI into your systems and watch the magic happen.”
Except there is no magic. There’s only math. And math requires the right inputs.
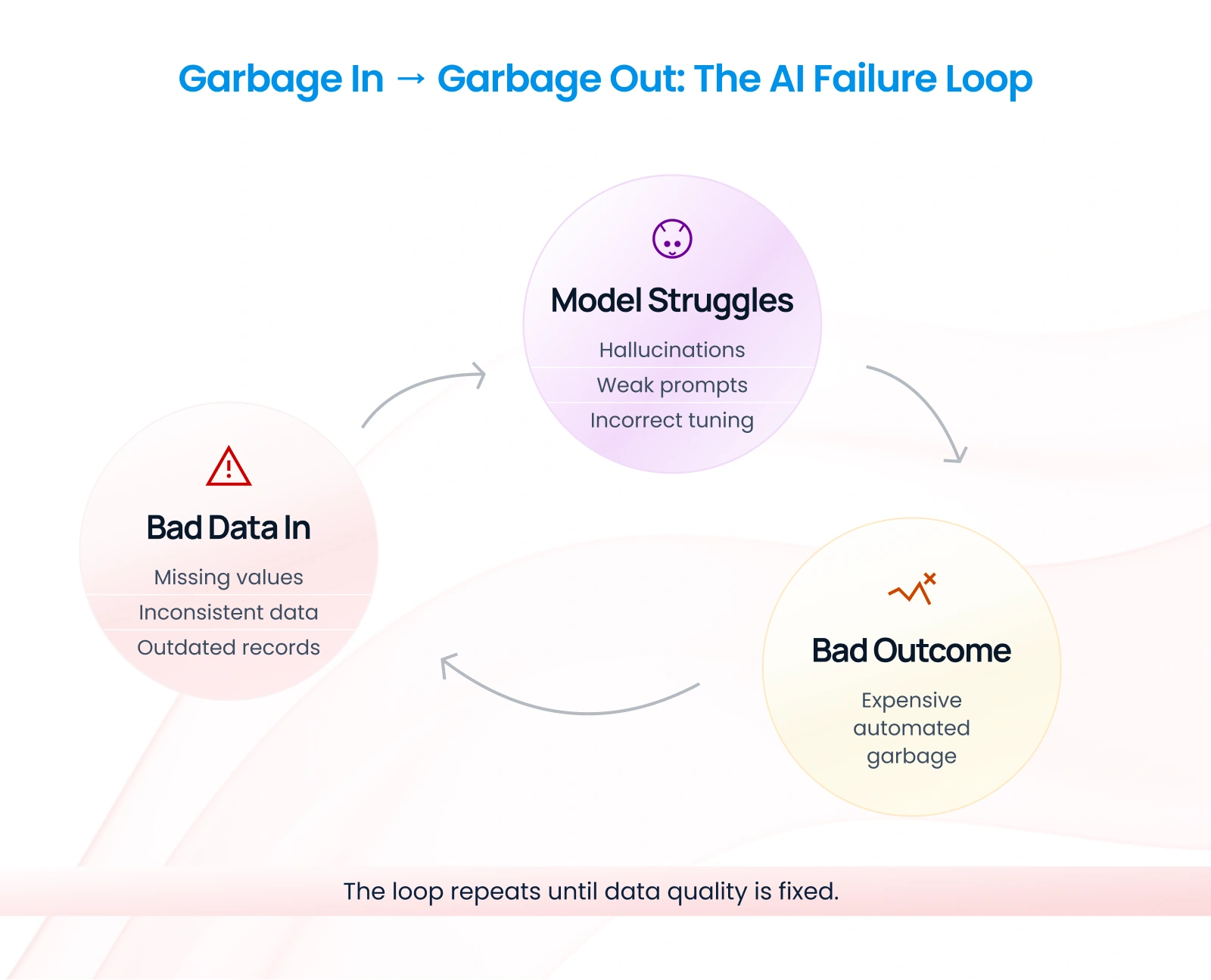
You can have the most sophisticated AI model in the world—trained on billions of parameters, powered by cutting-edge algorithms, built by the brightest minds in machine learning. But if you feed it garbage data? You get garbage outputs. Expensive, automated garbage.
The Questions No One Wants to Ask
Before you sign that AI contract, before you assemble that task force, before you announce your “AI transformation,” ask yourself:

Do we actually have the data?
Not “data” in the abstract sense. Not spreadsheets that exist somewhere. Not databases that technically contain information.
- Do we have the specific data needed to solve the problem we’re claiming AI will solve?
- If you want AI to predict customer churn, do you have historical customer behavior data? Transaction patterns? Support interactions? Or do you just have names and email addresses?
- If you want AI to optimize your supply chain, do you have granular data on lead times, supplier performance, demand patterns? Or do you have quarterly summaries in PowerPoint decks?
Is the data actually usable?
Here’s where organizations get brutally honest—or don’t.
- Is your data trapped in siloed systems that don’t talk to each other?
- Is it inconsistent (Customer ID “12345” in one system, “CUST-12345” in another)?
- Is it incomplete (missing values, partial records, gaps in time series)?
- Is it outdated (last updated when? Last validated when?)?
- Is it biased (reflecting past discrimination or systematic exclusions)?
- Is it labeled (if you need supervised learning, who’s done the labeling work)?
Is the data appropriate for AI to consume?
This is the question that separates real AI initiatives from theater.
AI models don’t read context. They don’t understand nuance. They don’t know that “N/A” and “null” and “0” and an empty field might all mean different things in your organization’s tribal knowledge.
They need:
- Structured formats they can parse
- Consistent schemas they can learn from
- Sufficient volume to identify patterns (not “big data” necessarily, but enough data)
- Representative samples that reflect the real-world scenarios they’ll encounter
- Clean labels if you’re doing supervised learning
- Temporal consistency if you’re making predictions over time
Your tribal knowledge doesn’t count. Your “it depends” scenarios don’t count. Your “well, usually we…” doesn’t count.
The Brutal Reality
Most organizations discover their data problems after they’ve committed to the AI initiative. After the budget is spent. After the vendor is hired. After the announcement is made.
Then comes the scrambling:
“We need to clean the data first.” “We need to integrate these systems.” “We need to establish data governance.” “We need to hire data engineers.”
These aren’t quick fixes. Data preparation isn’t a two-week sprint. It’s often 60-80% of the entire AI project timeline. And that’s if you’re lucky.
What Should You Do Instead?
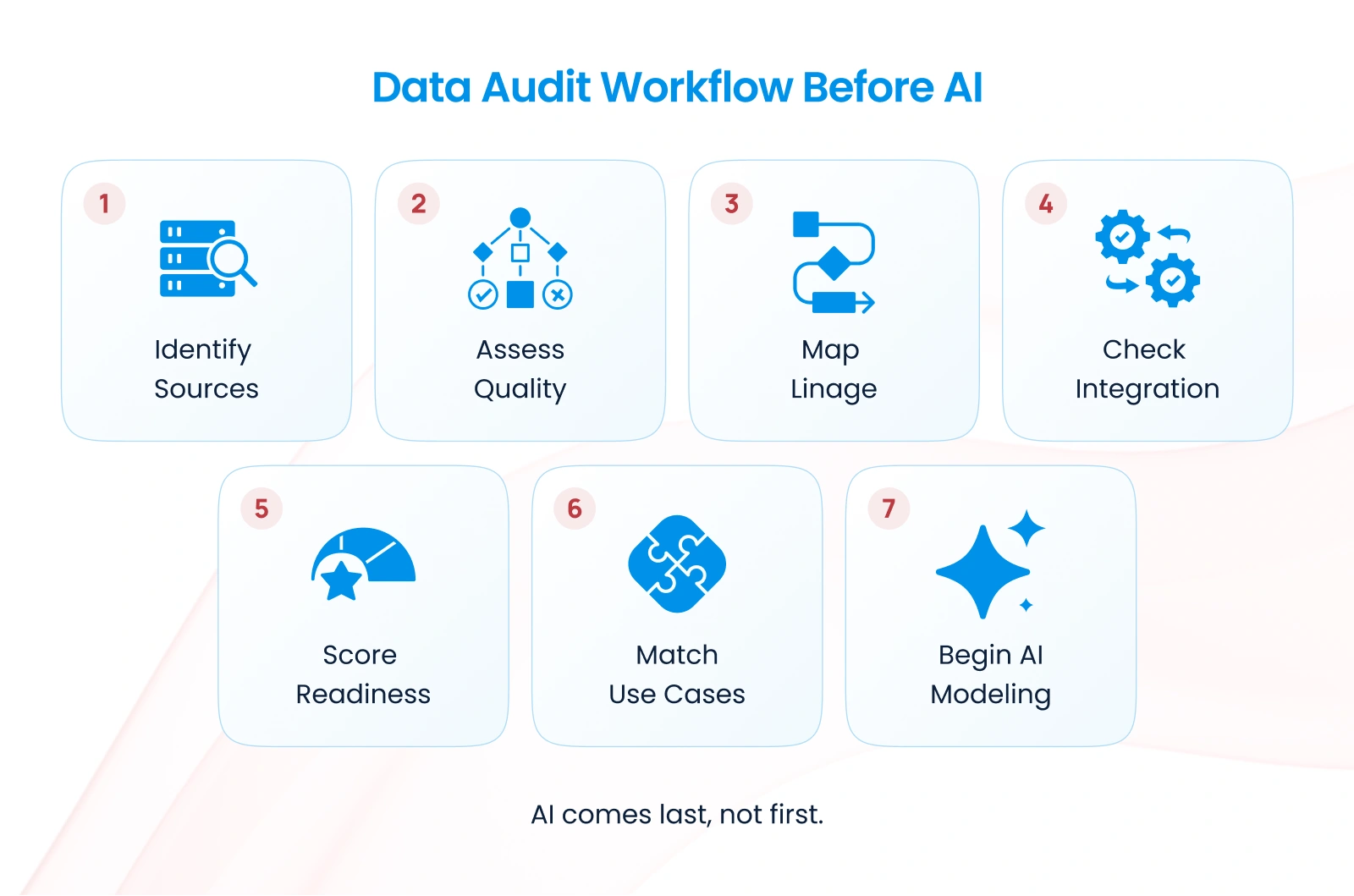
Start with a data audit, not an AI strategy.
Before you decide what AI can do for you, understand what data you have and what state it’s in.
Map your data landscape:
- What data do you collect?
- Where does it live?
- What’s its quality?
- What’s its volume?
- What’s its lineage?
- Who owns it?
- What are the gaps?
Match use cases to data reality, not aspirations.
Start with a data audit, not an AI strategy.
Before you decide what AI can do for you, understand what data you have and what state it’s in.
Invest in data infrastructure before AI infrastructure.
Unsexy? Absolutely. Less impressive in board meetings? You bet. More likely to succeed? Without question.
Data pipelines. Data quality tools. Data governance frameworks. Master data management. These aren’t obstacles to AI. They’re the foundation of AI.
The best AI initiatives are built on existing data strengths, not imagined future data states.
The Uncomfortable Truth
Most organizations aren’t ready for AI. Not because they lack vision or budget or executive support.
They’re not ready because they don’t have their data house in order.
And no amount of enthusiasm, vendor promises, or FOMO will change that fundamental reality.
The good news? Data readiness is achievable. It’s just work—unglamorous, detailed, sometimes tedious work. But it’s work that pays dividends not just for your AI initiatives, but for every data-driven decision your organization makes.
So before you embark on your next AI initiative, ask the hard questions about your data.
Because the most expensive AI failure is the one built on a foundation that was never there.
The question isn’t “Should we do AI?”
The question is “Is our data ready for AI to do anything meaningful?”
Answer that honestly, and you’ll save yourself millions in failed initiatives.
Kickstart Your AI Success Journey – Explore AI Command Center Today!
Search Blog
About us
CloudKitect revolutionizes the way technology startups adopt cloud computing by providing innovative, secure, and cost-effective turnkey AI solution that fast-tracks the digital transformation. CloudKitect offers Cloud Architect as a Service.
Related Resources

Evolution of AI [2024-2026]: From Generative Breakthroughs to Multi-Agent Orchestration
Muhammad Tahir
No Comments
Read More »

The Great Reversal: From Task Executors to Task Orchestrators
Muhammad Tahir
No Comments
Read More »