
Artificial Intelligence (AI) can seem complex with its specialized terminologies, but we can simplify these concepts by comparing them to something familiar: a car and its engine. Just as a car engine powers the vehicle and enables it to perform various tasks, the components of AI work together to produce intelligent outputs. Let’s dive or in other words drive into exploring key AI terminologies — and explain them using a car analogy.
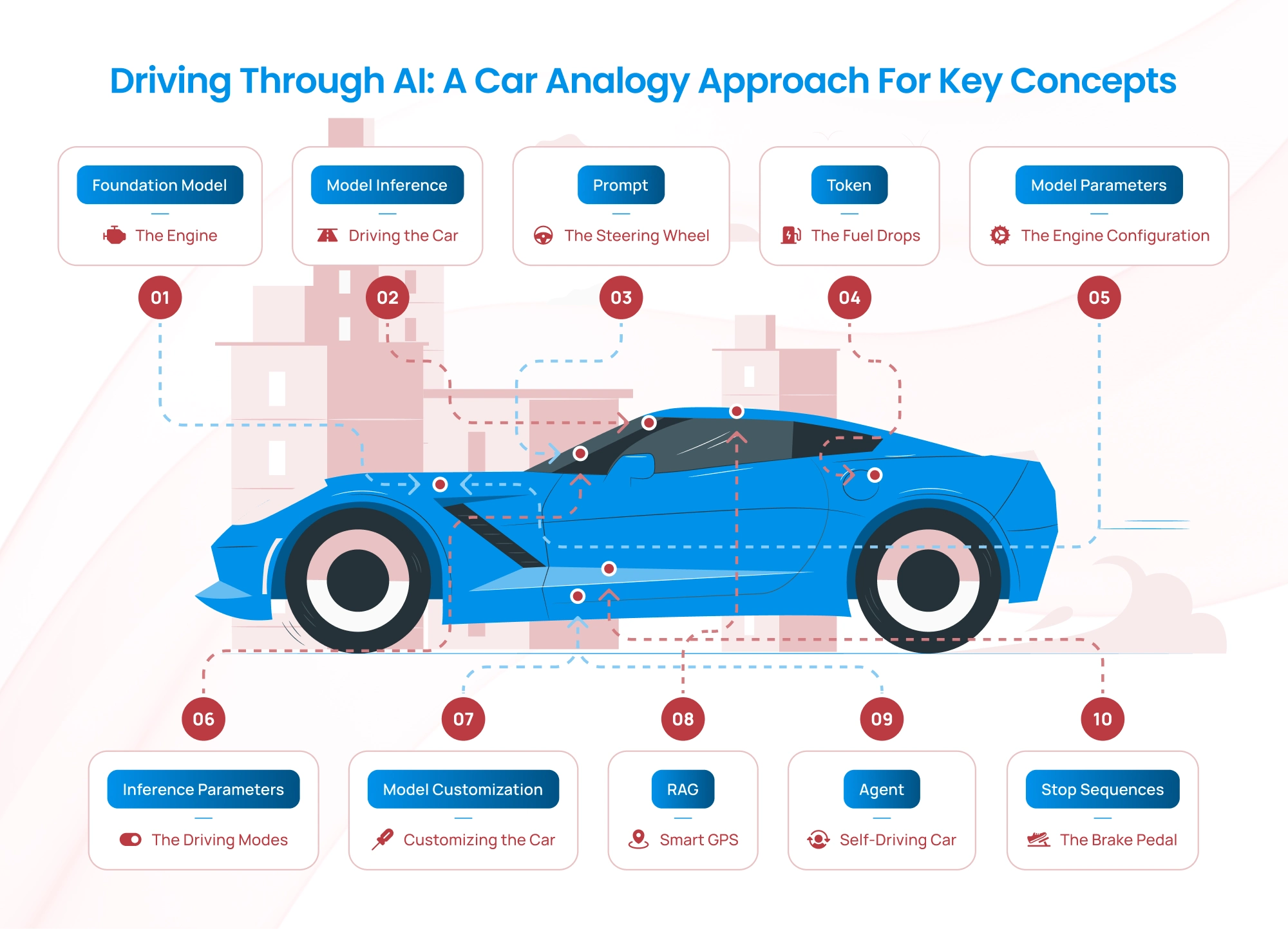
Driving Through AI: A Car Analogy Approach for Key Concepts
1. Foundation Model: The Engine
A Foundation Model is the AI equivalent of a car’s engine. It’s a large, pre-trained model that serves as the core of many AI applications. These models, like GPT or BERT, are trained on massive datasets and can handle a wide variety of tasks with minimal fine-tuning.
Car Engine Analogy:
Imagine the engine block in a car. It is carefully designed and built to provide the core functionality for the vehicle. However, this engine can power many different types of vehicles — from sedans to trucks — depending on how it’s fine-tuned and adapted. Similarly, a foundation model is pre-trained on vast amounts of data and can be adapted to perform specific tasks like answering questions, generating images, or writing text.
Real-World Example:
A foundation model like GPT-4 is trained on diverse internet data. Developers can adapt it for applications like chatbots, content creation, or code generation, just as a car engine can be adapted for different vehicles.
2. Model Inference: Driving the Car
Model Inference is the process of using a trained AI model to make predictions or produce outputs based on new input data. It’s like starting the car and driving it after the engine has been built and installed.
Car Engine Analogy:
Think of model inference as turning the ignition key and pressing the accelerator. The engine (foundation model) is already built and ready. When you provide input — like stepping on the gas pedal — the car (AI system) moves forward, performing the task you want. Similarly, during inference, the model takes your input data and produces a meaningful output.
Real-World Example:
When you type a question into ChatGPT, the model processes your query and generates a response. This act of processing your input to generate output is model inference — just like a car engine converting fuel into motion.
3. Prompt: The Steering Wheel
A Prompt is the input or instructions you give to an AI model to guide its behavior and output. It’s like steering the car in the direction you want it to go.
Car Engine Analogy:
The steering wheel in a car lets you decide the direction of your journey. Similarly, a prompt directs the foundation model on what task to perform. A well-crafted prompt ensures the AI stays on course and provides the desired results, much like a steady hand on the wheel ensures a smooth drive.
Real-World Example:
When you ask ChatGPT, “Tell me about a healthy diet,” that request is the prompt. The model interprets your instructions and produces a detailed response tailored to your needs. A precise and clear prompt results in better outcomes, just as clear directions help you reach your destination without detours.
4. Token: The Fuel Drops
In AI, a token is a unit of input or output that the model processes. Tokens can be words, parts of words, or characters, depending on the language model. They are the “building blocks” the model uses to understand and generate text.
Car Engine Analogy:
Imagine tokens as drops of fuel that power the car’s engine. Each drop of fuel contributes to the engine’s performance, just as each token feeds the model during inference. The engine processes fuel in small increments to keep running, and similarly, the AI model processes tokens sequentially to produce meaningful results.
Real-World Example:
When you type “High protein diet,” the model may break it into tokens like [“High”, “protein”, “diet”]. Each token is processed step-by-step to generate the output. These tokens are analogous to the steady flow of fuel drops that keep the car moving forward.
5. Model Parameters: The Engine Configuration
Model Parameters are the internal settings of the AI model that determine how it processes input and generates output. They are learned during the training process and define the “knowledge” of the model.
Car Engine Analogy:
Think of model parameters as the internal components and settings of the car’s engine, like the cylinder size, compression ratio, and fuel injection system. These elements define how the engine performs and responds under different conditions. Once the engine is built (the AI model trained), these components don’t change unless you rebuild or re-tune the engine (retrain the model).
Real-World Example:
A large model like GPT-4 has billions of parameters, which are essentially the learned weights and biases that allow it to perform tasks like text generation or translation. These parameters are fixed after training, just like a car’s engine components remain constant after manufacturing.
6. Inference Parameters: The Driving Modes
Inference Parameters are the settings you adjust during model inference to control how the model behaves. These include parameters like temperature (creativity level) and top-k/top-p sampling (how diverse the output should be).
Car Engine Analogy:
Inference parameters are like the driving modes in a car, such as “Eco,” “Sport,” or “Comfort.” These settings let you customize the car’s performance for different scenarios. For example:
- In “Eco” mode, the car prioritizes fuel efficiency.
- In “Sport” mode, it emphasizes speed and power. Similarly, inference parameters let you control whether the AI model produces more creative responses or sticks to conservative, predictable outputs.
Real-World Example:
When you interact with a model, setting the temperature to a higher value (e.g., 0.8) makes the model generate more diverse and creative outputs, like a sports car accelerating with flair. A lower temperature (e.g., 0.2) results in more deterministic and focused answers, like driving in “Eco” mode.
7. Model Customization: Customizing the Car
Model Customization refers to tailoring a pre-trained model to better suit specific tasks or domains. This can involve fine-tuning, transfer learning, or using specific datasets to adapt the model to unique needs.
Car Engine Analogy:
Imagine customizing a car to fit your driving style or specific requirements. You might:
- Install a turbocharger for more speed.
- Upgrade the suspension for off-road capabilities.
- Add a GPS for better navigation.
Similarly, model customization involves “tuning” the foundation model to specialize it for a particular task, like medical diagnosis or legal document analysis. Just as a car’s core engine remains the same but gains enhancements, the foundation model stays intact but becomes more effective for specific applications.
Real-World Example:
A general-purpose language model like GPT can be fine-tuned to specialize in technical writing for automotive manuals, akin to adding specialized tires to optimize the car for racing.
8. Retrieval Augmented Generation (RAG): Using a GPS with Real-Time Updates
Retrieval Augmented Generation (RAG) enhances a model’s ability to generate contextually accurate and up-to-date responses by integrating external knowledge sources during inference.
Car Engine Analogy:
Think of RAG as using a GPS system that retrieves real-time traffic and map data to guide you to your destination. While the car engine powers the movement, the GPS provides crucial external updates to ensure you take the best route, avoid traffic, and reach your goal efficiently.
Similarly, RAG-equipped AI models use external databases or knowledge sources to provide more accurate and informed responses. The foundation model generates the content, but the retrieved data ensures its relevance and accuracy.
Real-World Example:
If an AI model is asked about the latest stock prices, a standard model may struggle due to outdated training data. A RAG-enabled model retrieves the latest stock information from an external source and integrates it into the response, just as a GPS fetches real-time data to guide your route.
9. Agent: The Self-Driving Car
An Agent in AI refers to an autonomous system that can make decisions, take actions, and execute tasks based on its environment and goals, often without requiring human intervention.
Car Engine Analogy:
Imagine a self-driving car. It doesn’t just rely on the engine to move or the GPS for navigation; it combines everything — engine power, navigation data, sensors, and decision-making systems — to autonomously drive to a destination. It can adapt to changes in the environment (like traffic or weather) and make decisions in real time.
Similarly, an AI agent can autonomously complete tasks by combining a foundation model (engine), retrieval capabilities (GPS), and decision-making processes (autonomous systems). It operates like a self-driving car in the world of AI.
Real-World Example:
A customer service AI agent can handle a full conversation:
- Retrieve relevant policies from a knowledge base (RAG).
- Generate responses using a foundation model.
- Adapt to customer inputs and take appropriate actions, like escalating a case to a human if needed.
10. Stop Sequences: The Brake Pedal
A stop sequence in AI is like the brake pedal in a car. Just as the brake allows you to control when the car should stop, a stop sequence tells the AI model when to stop generating text. Without the brake, the car would continue moving indefinitely, and without a stop sequence, the model might generate irrelevant or overly lengthy responses.
Car Engine Analogy:
Imagine driving a car without brakes. You may reach your destination, but without a clear way to stop, you risk overshooting and creating chaos. Similarly:
- No Stop Sequence: The AI might generate an excessive amount of text, including irrelevant or nonsensical parts.
- With Stop Sequence: The model halts gracefully at the desired point, like a car coming to a smooth stop at a red light.
Real-World Example of Stop Sequences:
- Chatbot Applications: In a chatbot, a stop sequence like “\nUser:” might signal the model to stop responding when it’s the user’s turn to speak.
- Code Generation: For AI tools generating code, a stop sequence like “###” could indicate the end of a code snippet.
- Summarization: In summarization tasks, a stop sequence could be a period or a specific keyword that marks the end of the summary.
When setting up an AI system, choosing the right stop sequences is crucial for task-specific requirements. Just like learning to use the brake pedal effectively makes you a better driver, configuring stop sequences well ensures your AI outputs are precise and useful.
Bringing It All Together: The AI Car in Action
To understand how these elements work together, let’s imagine driving a car:
- The Foundation Model is like the engine block, providing the core power and functionality needed for the car to run. Without it, the car won’t move.
- Model Inference is the act of driving, where the engine converts fuel (input data) into motion (output).
- The Prompt is the steering wheel, guiding the car in the desired direction based on your instructions.
- Tokens are the fuel drops — the essential input units that the engine consumes to keep running.
- Model Parameters are the engine’s internal components — the fixed design that determines how the engine (model) operates.
- Inference Parameters are the driving modes — adjustable settings that influence how the car (model) performs under specific conditions.
- Model Customization is like upgrading the car to suit specific needs, enhancing its capabilities for specialized tasks.
- Retrieval Augmented Generation (RAG) is like using a GPS with real-time updates, integrating external information to make the journey smoother and more accurate.
- Agent is the self-driving car, autonomously combining engine power, GPS data, and environmental sensors to complete a journey.
- Stop Sequence: Stop sequences are a small but powerful tool in AI that keeps the system efficient, just as brakes are essential for a smooth driving experience
Final Thoughts
AI systems are like advanced cars with powerful engines, customizable components, and intelligent systems. Understanding AI terminologies becomes simpler when we draw parallels to familiar concepts like a car. By mastering these concepts, you’ll have the tools to navigate the AI landscape with confidence.
Happy driving — or, in this case, exploring the world of AI!
Talk to Our Cloud/AI Experts
Search Blog
About us
CloudKitect revolutionizes the way technology startups adopt cloud computing by providing innovative, secure, and cost-effective turnkey AI solution that fast-tracks the digital transformation. CloudKitect offers Cloud Architect as a Service.
Related Resources

Evolution of AI [2024-2026]: From Generative Breakthroughs to Multi-Agent Orchestration
Muhammad Tahir
No Comments
Read More »

The Great Reversal: From Task Executors to Task Orchestrators
Muhammad Tahir
No Comments
Read More »