
RAG (Retrieval-Augmented Generation): How It Works, Its Limitations, and Strategies for Accurate Results
- Blog
- Muhammad Tahir
In the rapidly advancing field of artificial intelligence, Retrieval-Augmented Generation (RAG) has emerged as a powerful approach to enhance language models. RAG integrates retrieval-based methods with generation-based methods, enabling more informed and context-aware responses. While RAG has revolutionized many applications like customer support, document summarization, and question answering, it isn’t without limitations.
This blog will explore what RAG is, how it works, its shortcomings in delivering highly accurate results, and alternative strategies to improve precision for your queries.
What is Retrieval-Augmented Generation (RAG)?
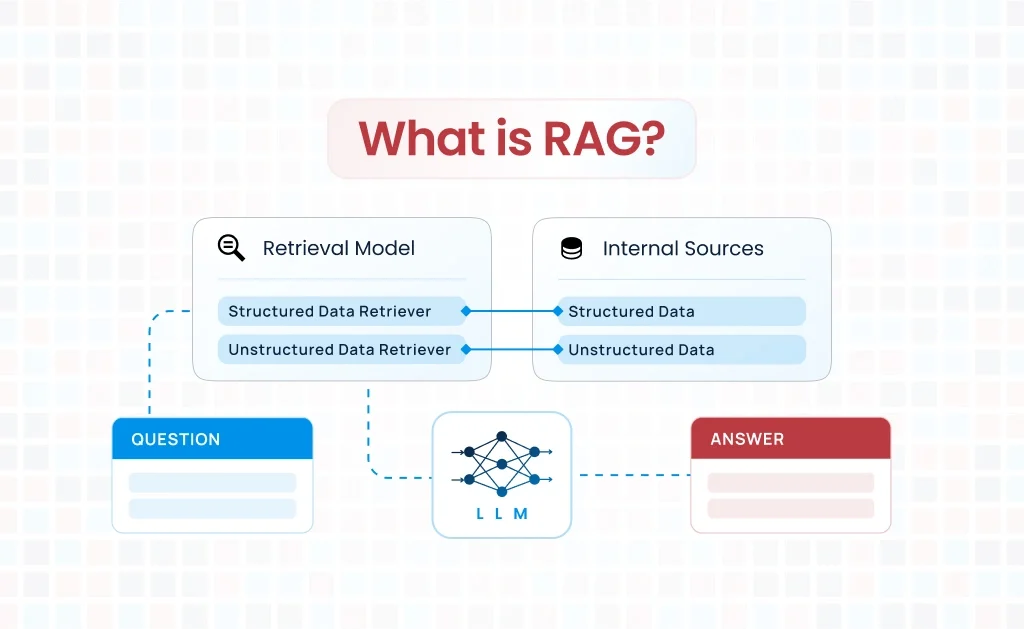
Retrieval-Augmented Generation is a hybrid AI framework that combines the strengths of retrieval systems (like search engines) with generative AI models (like GPT). Instead of relying solely on the generative model’s training data, RAG augments its responses by retrieving relevant external information in real time.
This approach allows RAG to:
- Access up-to-date and domain-specific knowledge.
- Generate more factually accurate and contextually relevant responses.
- Operate within dynamic and ever-changing environments.
Key Components of RAG:
1. Retriever
- The retriever locates relevant information from external sources, such as a database, vector search engine, or document corpus.
- This is often implemented using traditional search methods or semantic search powered by vector embeddings.
2. Generator
- The generative model processes the retrieved information, integrates it with the input query, and generates a human-like response.
- Models like GPT-4 or T5 are commonly used for this purpose.
3. RAG Workflow
- Input Query → Retriever fetches context → Context + Query → Generator produces response.
How Does RAG Work?
RAG’s functionality revolves around retrieving relevant data and incorporating it into the generative process. Here’s a step-by-step breakdown:
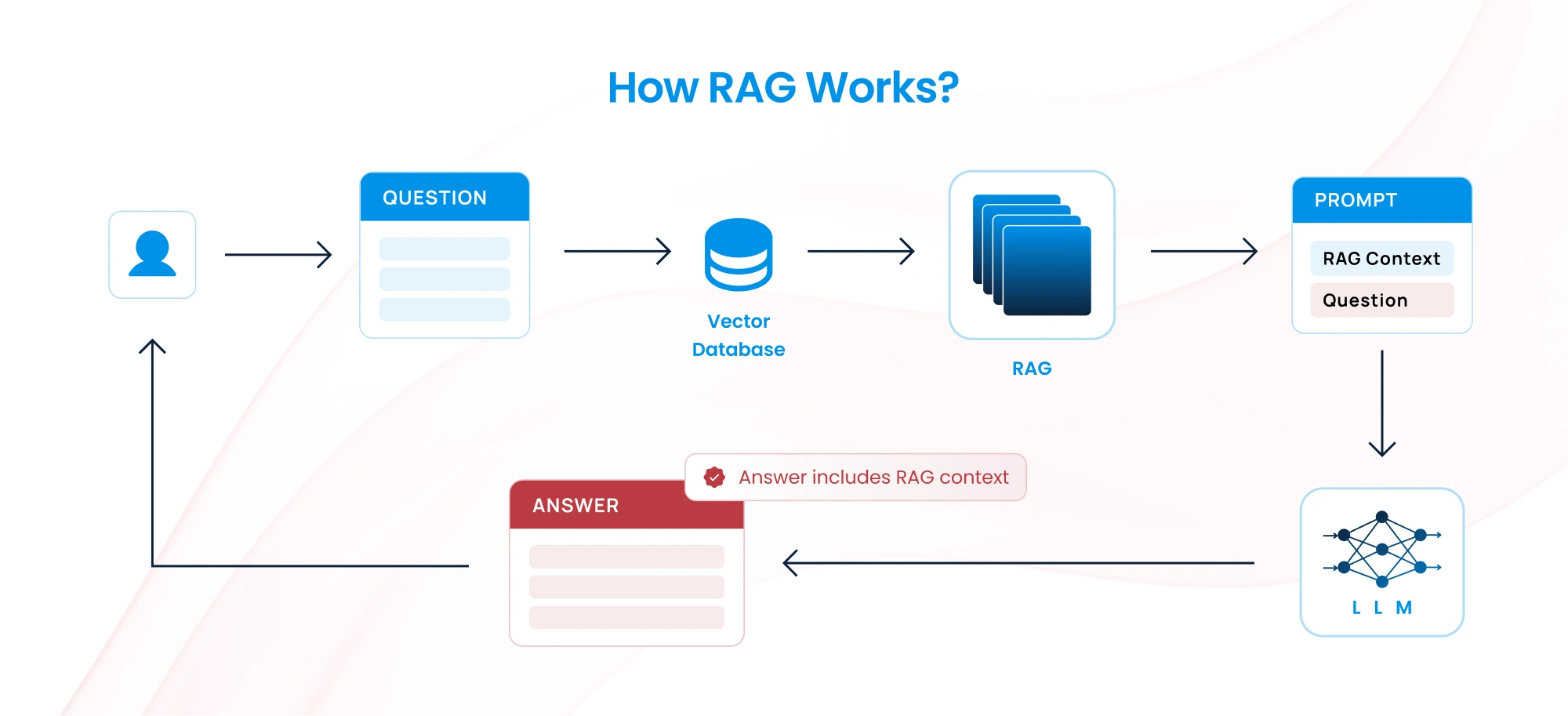
Step 1: Query Input
The user inputs a query. For example: “What are the benefits of green energy policies in the EU?”. For more details checkout our blog What is Prompt Engineering
Step 2: Retrieval
- The query is converted into a vector representation (embedding) and compared with vectors stored in a database or vector search engine.
- The retriever identifies documents or data points most relevant to the query.
For detailed analysis checkout our blog on How to Maximize Data Retrieval Efficiency
Step 3: Context Injection
The retrieved information is formatted and combined with the input query. This augmented input serves as the context for the generator.
Step 4: Generation
The generator uses both the query and the retrieved context to generate a response. For instance:
“Green energy policies in the EU promote sustainable growth, reduce carbon emissions, and encourage innovation in renewable technologies.”
Why RAG Is Not Sufficient for Accurate Results
While RAG enhances traditional generative models, it is not foolproof. Several challenges can undermine its ability to deliver highly accurate and reliable results.
1. Dependency on Retriever Quality
The accuracy of RAG is heavily dependent on the retriever’s ability to locate relevant information. If the retriever fetches incomplete, irrelevant, or low-quality data, the generator will produce suboptimal results. Common issues include:
- Outdated data sources.
- Lack of context in the retrieved snippets.
- Retrieval errors caused by ambiguous or poorly phrased queries.
2. Hallucination in Generative Models
Even with accurate retrieval, the generative model may hallucinate—generating content that is plausible-sounding but factually incorrect. This occurs when the model interpolates or extrapolates beyond the provided context.
3. Context Length Limitations
Generative models have fixed context length limits. When dealing with large datasets or long documents, relevant portions may be truncated, causing the model to miss critical details. For detailed analysis checkout our blog on Context Window Optimizing Strategies
4. Lack of Verification
RAG lacks built-in mechanisms to verify the factual correctness of its outputs. This is particularly problematic in domains where precision is paramount, such as medical diagnostics, legal analysis, or scientific research.
5. Domain-Specific Challenges
If the retriever’s database or vector store lacks sufficient domain-specific data, the system will struggle to generate accurate responses. For example, querying about cutting-edge AI research in a general-purpose RAG system may yield incomplete results.
Alternative Strategies for More Accurate Results
To overcome the limitations of RAG, organizations and researchers can adopt complementary strategies to ensure more reliable and precise outputs. Here are some approaches:
1. Hybrid Retrieval Systems
Instead of relying solely on one type of retriever (e.g., BM25 or vector search), hybrid retrieval systems combine traditional and semantic search techniques. This increases the likelihood of finding highly relevant data points.
Example:
- Use BM25 for exact keyword matches and vector search for semantic relevance.
- Combine their results for a more comprehensive retrieval.
2. Refinement-Based Prompting
The Refine approach involves generating an initial response and then iteratively improving it by feeding the output back into the system with additional context. This can address inaccuracies and enrich responses.
How it Works:
- Initial query → Generate draft response.
- Feed response + additional context back → Generate refined output.
3. Map-Reduce Approach
In the Map-Reduce strategy, the system retrieves multiple pieces of information, generates responses for each, and then aggregates the results. This is especially useful for complex or multi-faceted queries.
Steps:
- Map: Split the query into sub-queries and retrieve relevant information for each.
- Reduce: Synthesize the sub-responses into a final comprehensive answer.
4. Knowledge Validation with External APIs
Integrate RAG with external validation tools or APIs to cross-check facts and ensure accuracy. For instance:
- Use APIs like Wolfram Alpha for mathematical computations.
- Validate information against trusted databases like PubMed or financial regulatory data sources.
5. Specialized Vector Databases
Leverage vector databases tailored to specific domains, such as legal, healthcare, or finance. This ensures that the retriever has access to highly relevant and domain-specific embeddings.
Popular Vector Databases:
- Pinecone: Optimized for large-scale similarity search.
- Weaviate: Semantic search with schema-based organization.
- OpenSearch: High-performance vector database for AI applications. Our opensearch vector database blog dives into more details.
6. Combining RAG with Retrieval-Reranking
In this approach, retrieved results are re-ranked based on additional relevance scoring or contextual importance before being fed to the generative model. This minimizes irrelevant or low-quality inputs.
How it Works:
- Retrieval → Rerank results using scoring algorithms → Generate response.
7. Human-in-the-Loop (HITL)
Introduce a human oversight mechanism to validate the output. In high-stakes applications, a human expert can review and correct AI-generated responses before they are presented to the end-user.
8. Fine-Tuning on Domain Data
Fine-tune the generative model using domain-specific datasets to reduce hallucination and improve accuracy. This ensures the model generates responses aligned with specialized knowledge.
What is Retrieval-Augmented Generation (RAG)?
Use Case | Best Approach |
Dynamic knowledge retrieval | RAG with hybrid retrieval and reranking. |
Complex multi-step queries | Map-Reduce or Refine approach. |
High-stakes domains (e.g., medical) | Validation via APIs, HITL, and fine-tuned models. |
Need for semantic and contextual results | Vector databases with optimized embeddings. |
Need for real-time updates | RAG with access to frequently updated databases or APIs. |
Conclusion
Retrieval-Augmented Generation (RAG) is a transformative approach that has significantly enhanced the capabilities of generative AI models. By combining real-time retrieval with advanced language generation, RAG delivers context-aware and dynamic responses. However, its reliance on retriever quality, limitations in context length, and susceptibility to hallucination make it insufficient for scenarios demanding absolute precision.
To address these gaps, organizations should consider hybrid retrieval systems, advanced prompt engineering techniques like Map-Reduce or Refine, and domain-specific strategies such as fine-tuning and validation. By combining these approaches with RAG, businesses can achieve more accurate, reliable, and scalable knowledge search capabilities.
As AI continues to evolve, embracing a multi-faceted strategy will be crucial to unlocking the full potential of retrieval-based and generative technologies. Checkout our blog on How to use RAG to Chat With Your Private Data
Talk to Our Cloud/AI Experts
Search Blog
About us
CloudKitect revolutionizes the way technology startups adopt cloud computing by providing innovative, secure, and cost-effective turnkey AI solution that fast-tracks the digital transformation. CloudKitect offers Cloud Architect as a Service.

