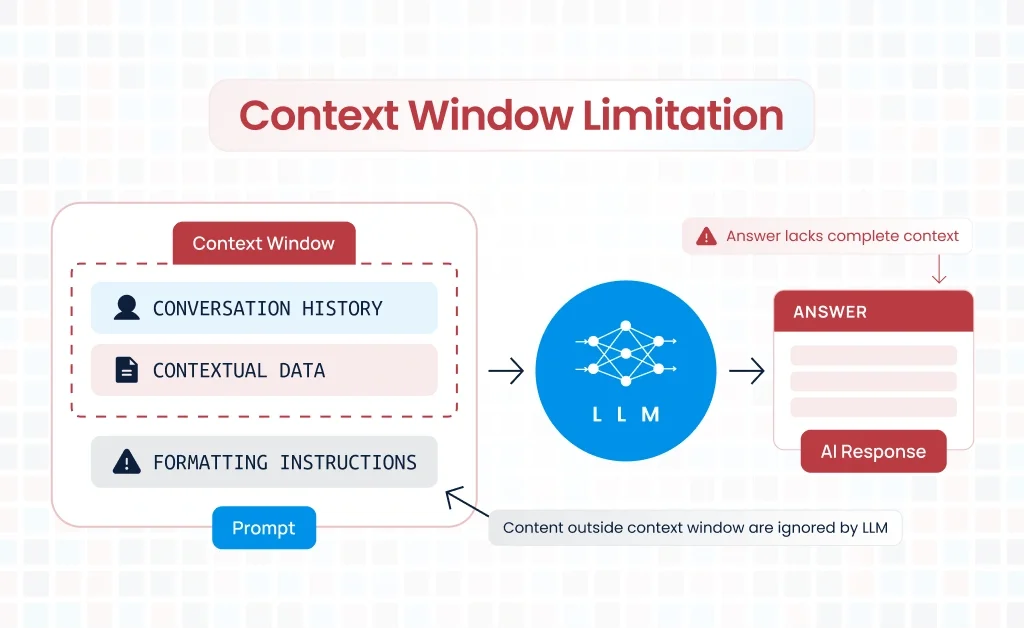

Generative AI models like GPT-4 are powerful tools for processing and generating text, but they come with a key limitation: a fixed-size context window. This window constrains the amount of data that can be passed to the model at once, which becomes problematic when dealing with large documents or data sets. When processing long documents, how do we ensure the AI can still generate relevant responses? In this blog post, we’ll dive into key strategies for addressing this challenge.
The Context Window Challenge in Generative AI
Before exploring these strategies, let’s define the problem. Generative AI models process text in segments, known as tokens, which represent chunks of text. GPT-4, for example, can handle up to around 8,000 tokens (depending on the model). This means if you’re dealing with a document longer than this, you need to pass it to the model in parts or optimize the input to fit within the available token space.
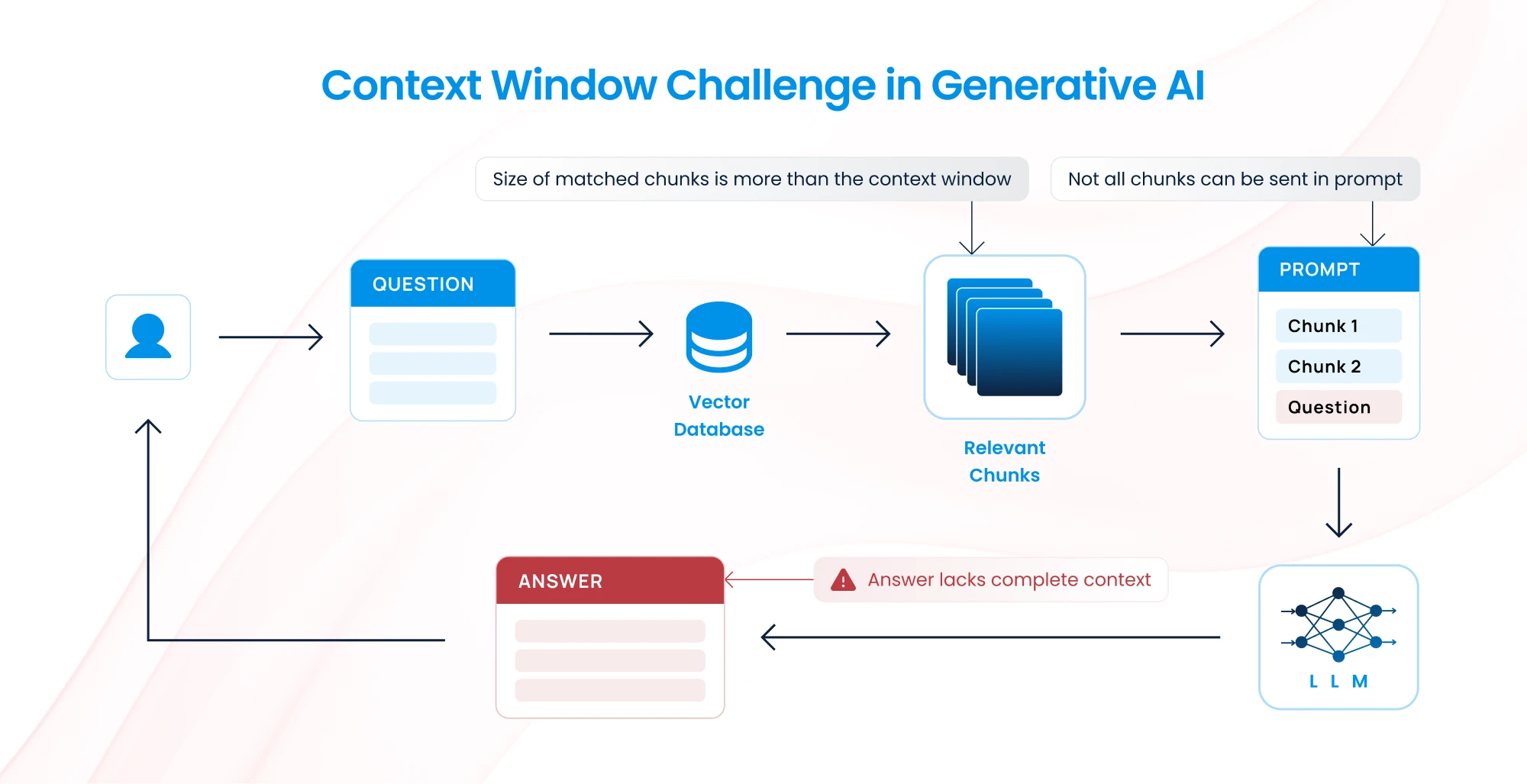
The challenge then becomes: How do we ensure the model processes the document in a way that retains relevance and coherence? This is where the following strategies shine.
1. Chunking or Splitting the Text
- How It Works: Divide a long document into smaller, manageable chunks that fit within the context window size. Each chunk is processed separately.
- Challenge: Maintaining the relationship between different chunks can be difficult, leading to potential loss of context across sections.
- Best for: Summarization, processing long documents in parts.
Example: You have a 10,000-word research paper, but your LLM can only handle 2,000 words at a time. Split the paper into five chunks of 2,000 words each and process them independently. After processing, you can combine the outputs to form a coherent result, though some manual review may be needed to ensure the entire context is captured.

Use Case: Processing long legal documents or research papers.
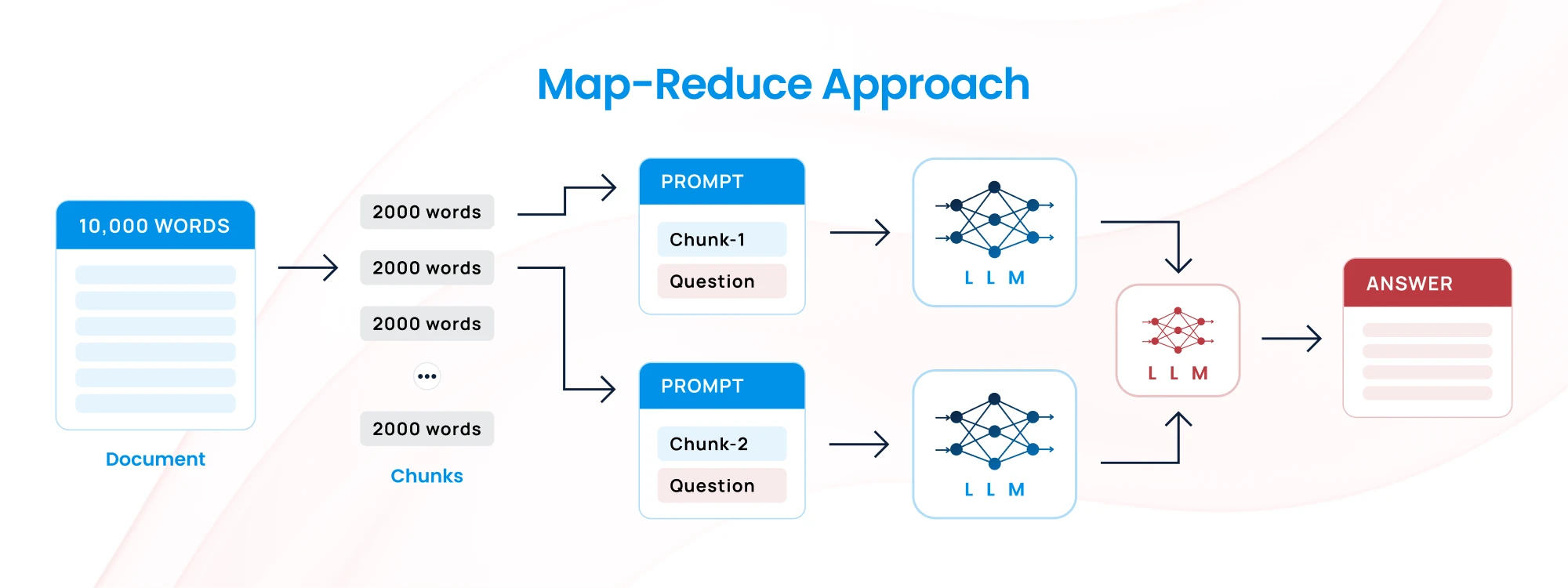
2. Map-Reduce Approach
- How It Works: Break the text into chunks (map), process each chunk independently, and then combine the outputs (reduce) into a final coherent result.
- Challenge: While scalable, it may lose some nuanced context if not handled carefully.
- Best for: Document summarization, large-scale text generation.
Example: For a company with a large set of customer feedback, you split the feedback into smaller chunks, process each chunk (mapping phase) to generate summaries or insights, and then combine these summaries into a final, unified report (reduce phase).
Use Case: Summarizing large datasets, generating high-level reports from unstructured text data.
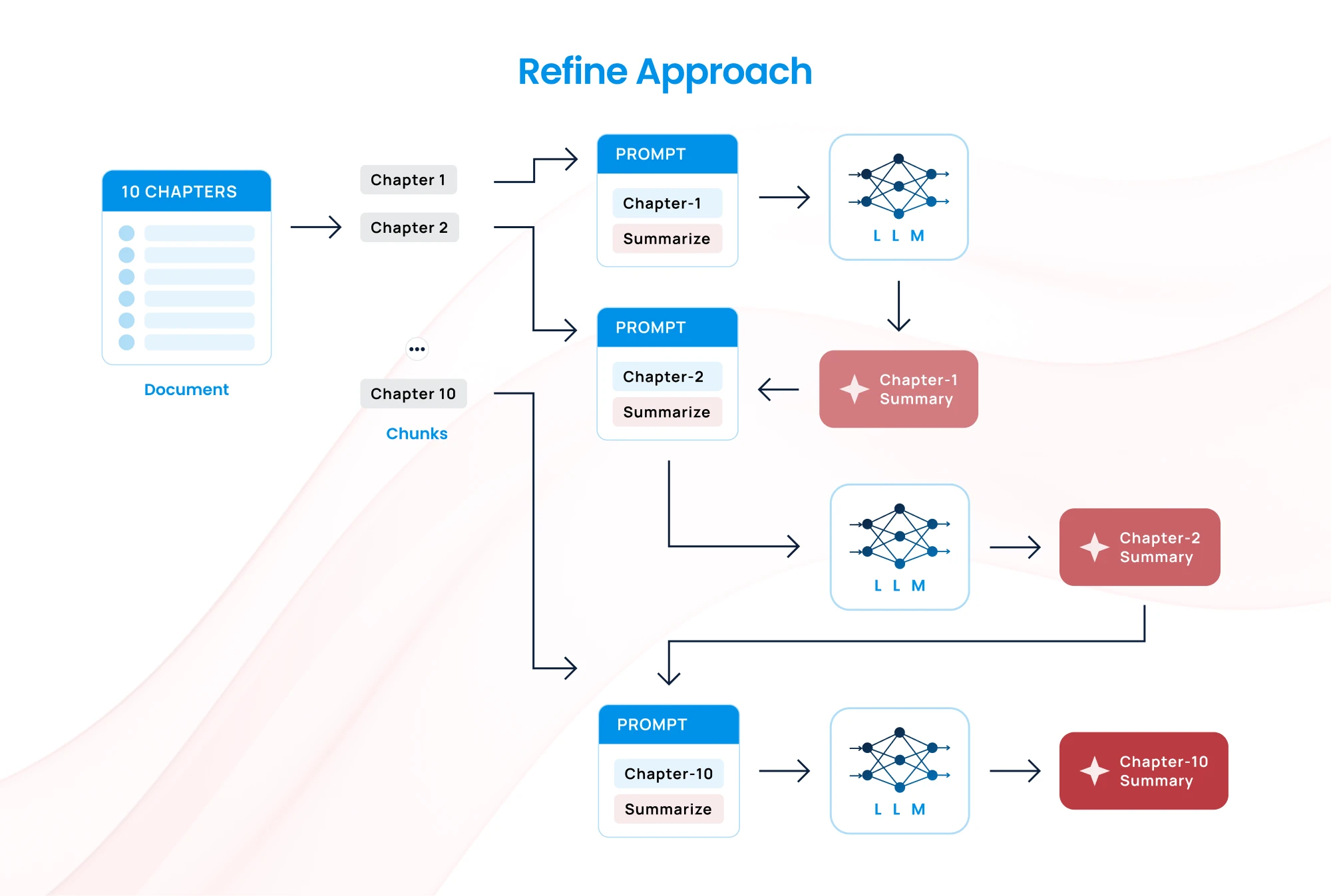
3. Refine Approach
- How It Works: Iteratively process chunks, where each output is refined in the next step by adding new information from subsequent chunks.
- Challenge: Can be slower since each step depends on the previous one.
- Best for: Tasks requiring detailed and cohesive responses across multiple sections, such as legal or technical document processing.
Example: When analyzing a long novel, you pass the first chapter to the model and get an initial output. You then pass the second chapter along with the output of the first, allowing the model to refine its understanding. This process continues iteratively, ensuring that the context builds as the model processes each chapter.
Use Case: Reading comprehension of multi-chapter books or documents where sequential context is important.
4. Map-Rerank Approach
- How It Works: Split the document into chunks, process each, and rank the outputs based on relevance to a specific query or task. The highest-ranked chunks are processed again for final output.
- Challenge: Requires a robust ranking system to identify the most relevant content.
- Best for: Question-answering systems or tasks where prioritizing the most important information is critical.
Example: You have a large technical manual and need to answer a specific query about “installation procedures.” Break the manual into chunks, process them to extract information, and rank the chunks based on how relevant they are to the “installation procedures.” The top-ranked chunks are then further processed to generate a detailed response.
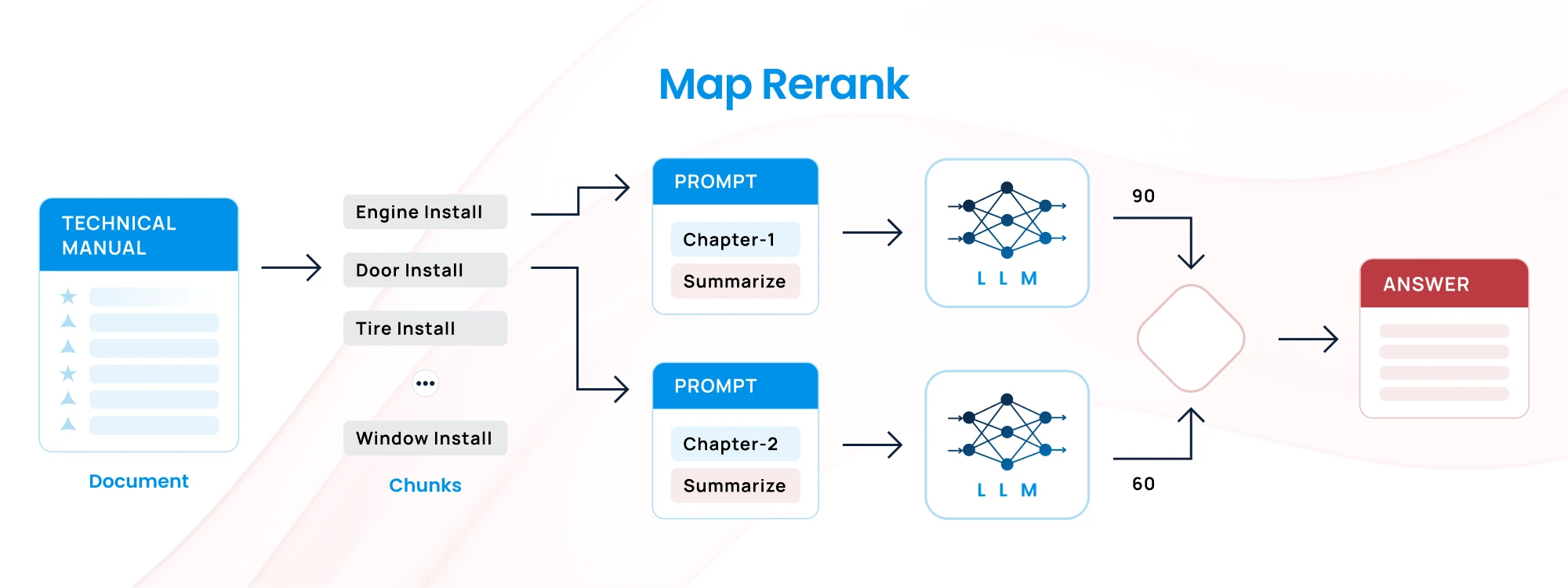
Use Case: Customer service or technical support, where relevance to specific queries is critical.
5. Memory Augmentation or External Memory
- How It Works: Use external memory systems, such as a knowledge database or external API, to offload information that doesn’t fit in the context window and retrieve it when needed.
- Challenge: Requires building additional systems to store and query relevant information.
- Best for: Large, complex workflows requiring additional context beyond what the model can handle in one window.
Example: When generating detailed financial reports, use an external database that contains prior financial information and trends. Instead of feeding all the data directly into the LLM, the model queries this database for relevant information when needed.
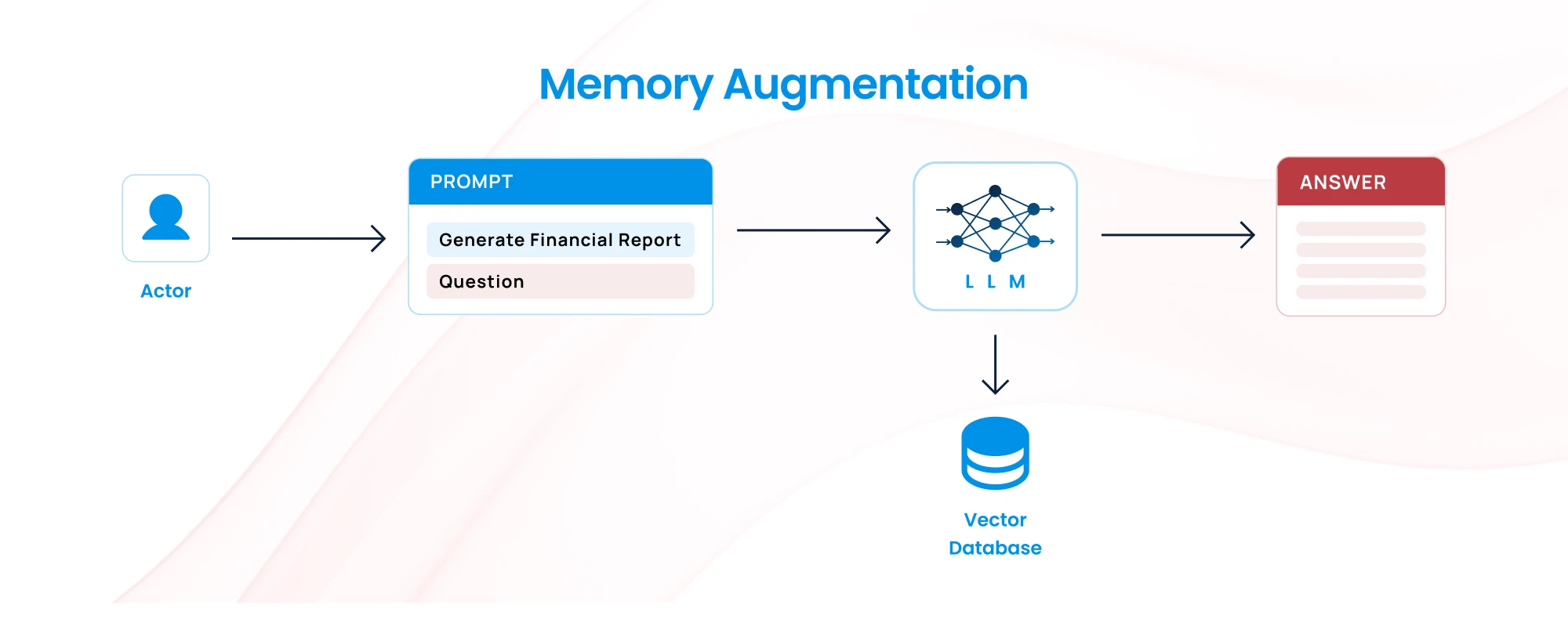
Use Case: Financial analysis or technical documentation where information needs to be retrieved from large databases.
6. Hybrid Strategies
- How It Works: Combine multiple methods such as chunking with refining or map-reduce with reranking to create a tailored solution for your specific use case.
- Challenge: Complexity in implementing the right combination of strategies.
- Best for: Custom applications with diverse document types and tasks.
Example: For a legal analysis task, you first use Chunking to split a 200-page contract. Then, for each chunk, you apply the Refine method, allowing the model to build on previous chunks’ outputs. Finally, you use Map-Rerank to prioritize and analyze the most important sections for a specific query (e.g., “termination clauses”).
Use Case: Combining multiple methods for tasks involving long, complex documents, such as legal or policy analysis.
7. Prompt Engineering with Contextual Prompts
- How It Works: Use carefully designed prompts that include summaries or key points to set the context for the model. This minimizes the amount of irrelevant information fed into the model.
- Challenge: Requires skill in prompt crafting and may not always capture the necessary context.
- Best for: Direct responses to specific tasks or queries, reducing the need to input entire documents.
Example: Instead of feeding an entire scientific paper into the model, craft a detailed prompt that summarizes the background and key points of the paper. This reduces the amount of information needed while still allowing the model to generate relevant responses.
Prompt Example: “Summarize the key findings of a study that explores the effects of AI on workplace productivity. The study covers both positive and negative impacts, with detailed metrics on employee performance.”
Choosing the Right Strategy
Each of these strategies has its strengths and weaknesses, and the right choice depends on the nature of the task you’re tackling.
Managing the context window limitation in LLMs is essential for effectively using generative AI models in document-heavy or context-sensitive tasks. Depending on your specific use case—whether it’s summarization, document understanding, or task-specific query processing—one or more of these strategies can help optimize model performance while working within the constraints of the context window.
Talk to Our Cloud/AI Experts
Search Blog
About us
CloudKitect revolutionizes the way technology startups adopt cloud computing by providing innovative, secure, and cost-effective turnkey AI solution that fast-tracks the digital transformation. CloudKitect offers Cloud Architect as a Service.

